Problem: You Can't Reliably Tell If Text Was AI-Generated
You need to know whether a document, essay, or report was written by a human or an LLM. Existing detectors give false positives on non-native English writers and fail after minor edits. Watermarking promises a better answer — but the reality is complicated.
You'll learn:
- How the three main AI watermarking approaches work under the hood
- Why each method breaks down in practice
- What the current state of the art actually delivers (and where it fails)
Time: 20 min | Level: Intermediate
Why This Happens
Detecting AI text after the fact is a fundamentally hard problem: LLMs produce fluent, human-like output, and any statistical fingerprint can be erased by paraphrasing.
Watermarking approaches this differently — instead of detecting AI text forensically, you embed a signal during generation that survives reasonable edits. The challenge is making that signal robust without degrading output quality.
Three approaches dominate current research:
- Token-level statistical watermarks (embed signal in token selection)
- Semantic watermarks (embed signal in meaning/structure)
- Post-hoc steganography (add signal after generation)
Common symptoms that motivate this problem:
- Detectors like GPTZero flag human-written technical prose as AI
- Simple paraphrasing defeats most watermarking schemes
- No watermark survives translation and back-translation intact
How Token-Level Watermarking Works
Step 1: The "Green/Red List" Method
The most influential technique comes from a 2023 paper by Kirchenbauer et al. (UMD). The idea is elegant:
# Pseudocode - not a real implementation
def generate_token_with_watermark(logits, prev_token, key):
# Deterministically split vocabulary into green/red lists
# using the previous token as a seed
green_list, red_list = split_vocab(vocab, seed=hash(prev_token, key))
# Boost logits for green-list tokens
logits[green_list] += delta # delta ~= 2.0
# Sample as normal - green tokens now more likely
return sample(softmax(logits))
The key insight: a legitimate LLM output will have statistically too many "green" tokens. You can detect this with a z-score test — no access to the model required, just the secret key.
Expected: Detection accuracy >95% on unmodified text, with false positive rate <1% at z=4.
If detection fails:
- Low z-score on genuine watermarked text: Delta was set too low, or text is very short (<200 tokens)
- False positives on human text: Key collision — try a different key or raise the threshold
Step 2: Why It Breaks Under Paraphrasing
# Attack: paraphrase with a different LLM
watermarked_text = generate_with_watermark(prompt)
attacked_text = paraphrase_llm(watermarked_text)
# Result: z-score drops from ~8 to ~1.5
# Watermark is effectively destroyed
Even light paraphrasing (synonym substitution, sentence reordering) disrupts the token-level signal. The green/red list assignment is tied to specific tokens — change the tokens, lose the watermark.
This is the core weakness of all token-level approaches.
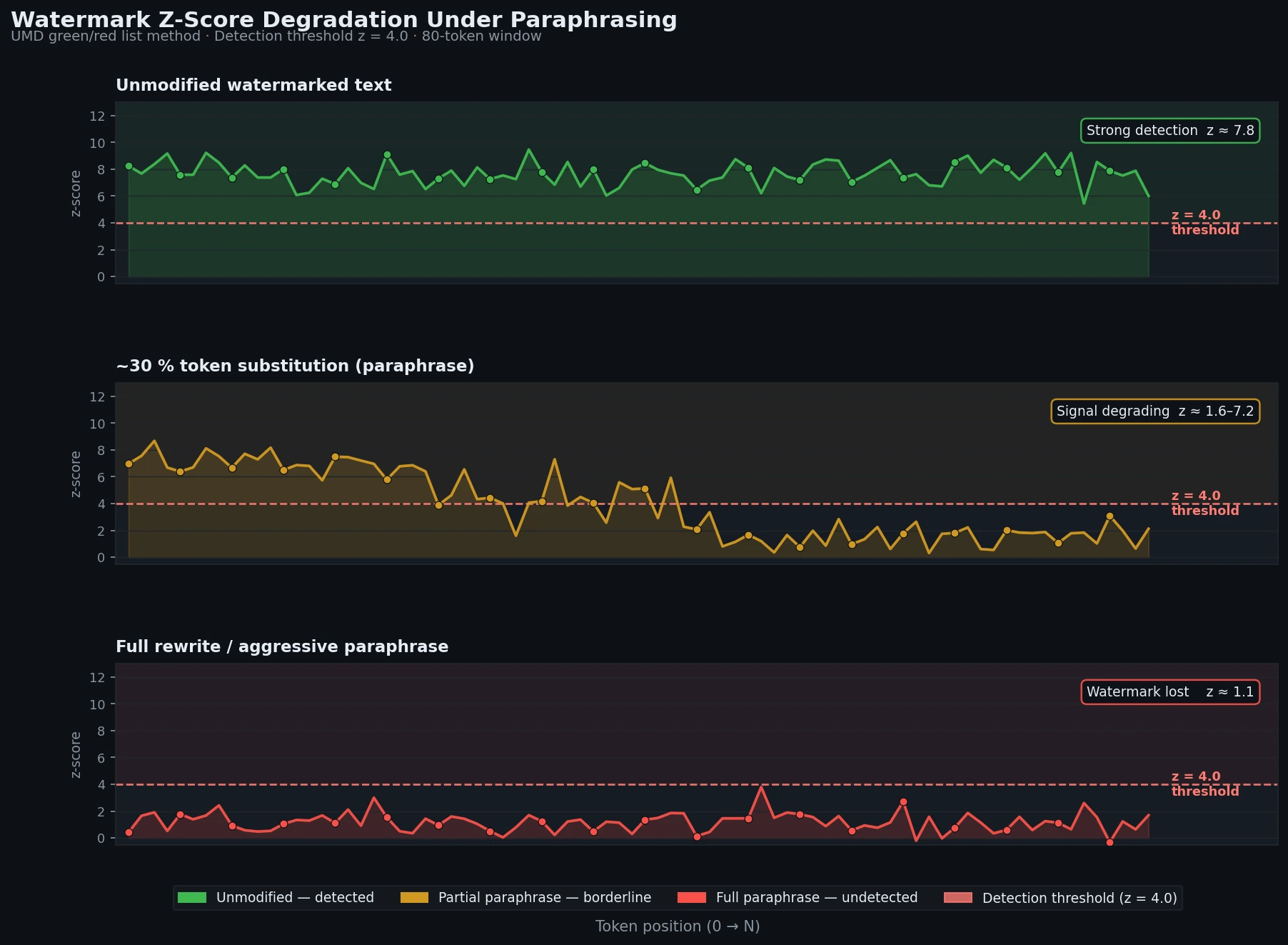 Z-score drops below detection threshold after ~30% of tokens are substituted
Z-score drops below detection threshold after ~30% of tokens are substituted
Semantic Watermarking
Step 1: Embed Signal in Meaning, Not Tokens
Semantic watermarks encode information in choices that are meaning-preserving but detectable:
# Conceptual example: encode watermark bit in sentence structure
def encode_bit(sentence, bit):
if bit == 0:
# Use active voice
return to_active_voice(sentence)
else:
# Use passive voice
return to_passive_voice(sentence)
# Decode: check voice distribution across document
def detect_semantic_watermark(text):
active_count = count_active_sentences(text)
passive_count = count_passive_sentences(text)
# Significant imbalance suggests watermark
return chi_squared_test(active_count, passive_count)
Real implementations use dozens of such binary choices (synonym selection, clause ordering, anaphora resolution) to encode a multi-bit payload.
Expected: Survives paraphrasing better than token-level — roughly 60-70% bit recovery after moderate paraphrasing vs. ~10% for token-level.
If recovery rate is too low:
- Document is too short: Need ~500+ words for reliable multi-bit payload
- Aggressive paraphrasing: Semantic watermarks still fail against full rewriting
Step 2: The Quality vs. Robustness Tradeoff
# Strong watermarks require constrained generation
# This hurts output quality
# Weak watermark (high quality, easy to remove)
watermark_strength = 0.1 # Small preference for watermarked choices
perplexity_increase = 2% # Barely noticeable
# Strong watermark (detectable after edits, lower quality)
watermark_strength = 0.8 # Heavy preference for watermarked choices
perplexity_increase = 15% # Noticeably worse text
There's no free lunch: robustness comes at the cost of text quality, and a determined attacker with a strong paraphrase model can strip most semantic signals.
Cryptographic and Post-Hoc Approaches
What Works (And What Doesn't)
Post-hoc steganography (embedding a watermark after generation using whitespace, Unicode variation selectors, zero-width characters) is trivially defeated:
# Strip all zero-width and invisible Unicode
echo "$text" | python3 -c "
import sys, unicodedata
text = sys.stdin.read()
cleaned = ''.join(c for c in text if unicodedata.category(c) != 'Cf')
print(cleaned)
"
Any copy-paste through a plain text editor, HTML sanitizer, or PDF render will strip the signal.
Cryptographic watermarking (signing model outputs with a private key) does work — but only if you control the distribution channel. If the LLM provider signs outputs and the consumer verifies against a public key, provenance is guaranteed. This is the approach C2PA and the Coalition for Content Provenance are pushing.
The problem: it requires cooperation from both the generator and a trust infrastructure. It proves this model generated this text — but doesn't survive any editing.
 C2PA trust chain: model signs at generation, verifier checks against published key
C2PA trust chain: model signs at generation, verifier checks against published key
Verification
What You Can Actually Test Today
# Test UMD watermark implementation (open source)
pip install extended-watermark-processor
python3 -c "
from extended_watermark_processor import WatermarkLogitsProcessor, WatermarkDetector
# Detection example
detector = WatermarkDetector(
vocab_size=50257,
gamma=0.25, # Fraction of vocab in green list
seeding_scheme='simple_1',
device='cpu',
tokenizer=tokenizer,
z_threshold=4.0 # Detection threshold
)
score = detector.detect(text)
print(f'z-score: {score[\"z_score\"]:.2f}, detected: {score[\"prediction\"]}')
"
You should see: A z-score >4.0 on unmodified watermarked text, <2.0 on human text (with caveats on short documents).
What You Learned
- Token-level watermarks (UMD green/red list) are the most practical today but fail after paraphrasing
- Semantic watermarks are more robust but degrade output quality and still don't survive aggressive rewriting
- Cryptographic/C2PA approaches give strong provenance guarantees but require infrastructure and don't survive editing
- No current method reliably watermarks text that will be edited, translated, or paraphrased
Limitation: All watermarking research assumes the generator cooperates. An adversarial actor using a local, unwatermarked model produces undetectable output by definition.
When NOT to use watermarking: Don't rely on it for high-stakes decisions (academic integrity, legal evidence) without understanding its failure modes. It's a probabilistic signal, not a cryptographic proof — except in the C2PA case.
Based on research current as of early 2026. Key papers: Kirchenbauer et al. 2023 (UMD), Christ et al. 2023 (undetectable watermarks), Kuditipudi et al. 2023 (robust watermarks). C2PA spec v2.1.