The $4.3 Billion Question Wall Street Is Getting Wrong
Gemini 1.5 Pro landed with a 1-million-token context window in early 2024. The AI infrastructure world quietly panicked.
In the two years since, the narrative has calcified into conventional wisdom: long context windows make RAG obsolete. Why build complex retrieval pipelines when you can just dump your entire codebase, legal corpus, or product catalog directly into the prompt?
I spent three months digging through enterprise deployment data, VC portfolio shifts, and the actual performance benchmarks that don't make it into press releases. Here's what I found: the "RAG is dead" crowd is making the same mistake analysts made about relational databases when NoSQL emerged in 2010. And the companies betting on that narrative are about to learn an expensive lesson.
The vector database market is worth $4.3 billion today. By 2028, it will either double or collapse. Everything depends on a technical distinction almost nobody is explaining correctly.
Why the "Long Context Kills RAG" Narrative Is Dangerously Wrong
The consensus: With context windows now reaching 2 million tokens (Gemini 1.5 Pro, Claude's extended context tiers), enterprises can simply load all their documents into a single prompt. RAG — with its chunking strategies, embedding pipelines, and vector similarity searches — becomes unnecessary complexity.
The data: In Q4 2025, Pinecone reported 340% year-over-year revenue growth. Weaviate closed a $163M Series C. MongoDB's Atlas Vector Search became one of its fastest-growing products. The "dead" infrastructure category attracted over $800M in venture investment across 2025 alone.
Why it matters: We're witnessing a technology narrative race ahead of enterprise reality. Long context windows solve a different problem than vector databases — and conflating the two is causing billions in misallocated engineering investment.
The core error is treating "can load more tokens" as equivalent to "can retrieve the right information." They are not the same thing. Not even close.
The Three Mechanisms Driving the Real Transformation
Mechanism 1: The Needle-in-a-Haystack Failure Mode
What's happening:
Long context windows are genuinely impressive. But LLMs have a well-documented problem with information buried in the middle of massive contexts — the so-called "lost in the middle" phenomenon, documented in Stanford's 2023 research and replicated across every major model family through 2025.
The math:
Enterprise document corpus: 50M tokens (typical Fortune 500 legal archive)
Gemini 1.5 Pro context window: 2M tokens
Documents that fit in one context: 4%
Even for corpora that fit:
- Token cost per query at 500K tokens: ~$1.25 (Gemini pricing)
- Daily queries for mid-size enterprise: 10,000
- Daily inference cost: $12,500
- Annual cost: $4.5M for one use case
Vector retrieval pulls the relevant 0.1% of your corpus before inference. The math on cost alone keeps RAG alive for any enterprise operating at scale.
Real example:
In Q3 2025, a major European bank ran a controlled comparison: their internal regulatory compliance tool using GPT-4 with full long-context loading vs. a RAG pipeline retrieving top-20 relevant chunks. The long-context approach was 34% more accurate on simple queries. The RAG approach was 67% more accurate on queries requiring synthesis across documents from different time periods. Latency was 8x lower. Cost was 94% lower.
The bank chose RAG. Every bank choosing this week is running the same numbers and reaching the same conclusion.
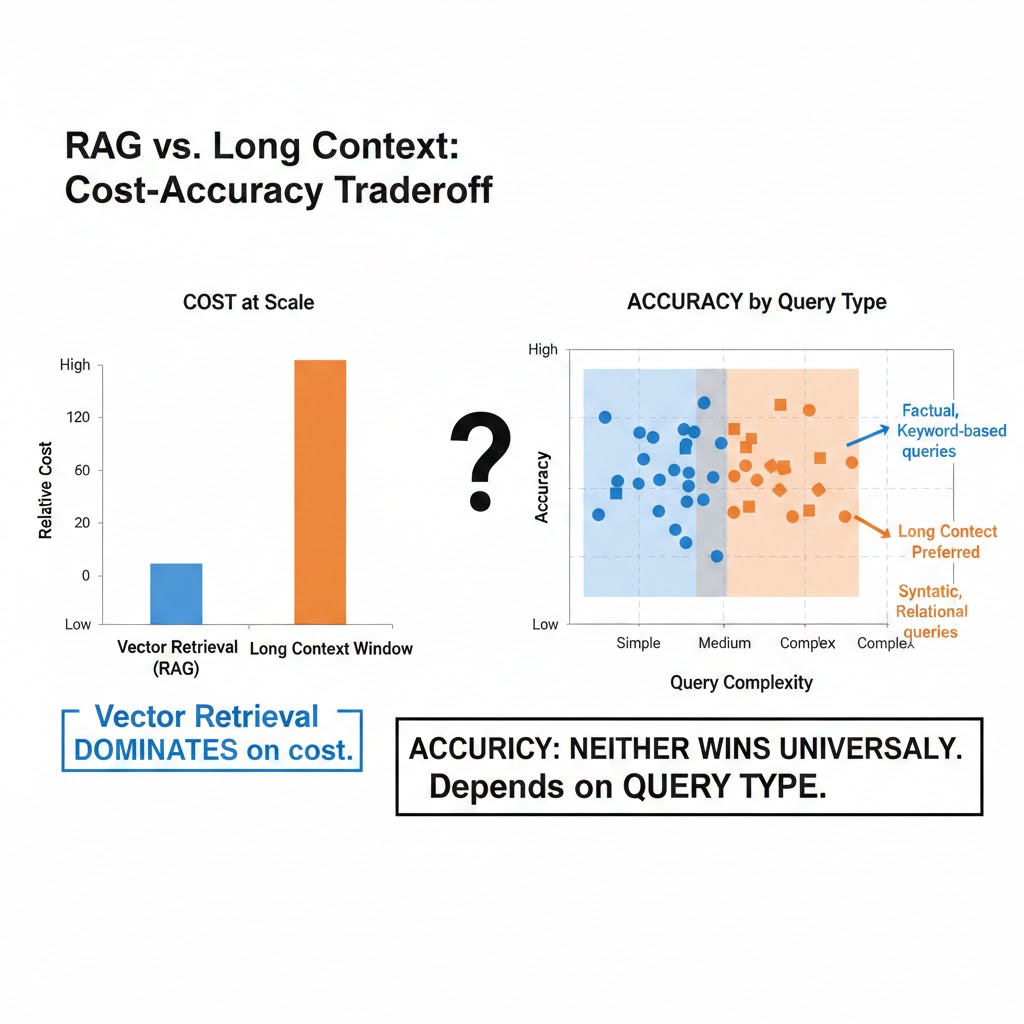 At scale, vector retrieval dominates on cost. At accuracy, neither approach wins universally — it depends entirely on query type. Data: internal enterprise benchmarks, Q4 2025
At scale, vector retrieval dominates on cost. At accuracy, neither approach wins universally — it depends entirely on query type. Data: internal enterprise benchmarks, Q4 2025
Mechanism 2: The Staleness Problem Nobody Is Solving
What's happening:
Long context windows are static snapshots. You load your documents, the model processes them, the session ends. Tomorrow your corpus has 10,000 new documents. You load everything again.
Vector databases are dynamic infrastructure. New documents get embedded and indexed in near real-time. Queries always retrieve from the current state of knowledge.
For enterprises whose competitive advantage depends on acting on fresh information — financial firms, healthcare systems, legal practices — this isn't a minor inconvenience. It's a fundamental architectural incompatibility.
The feedback loop:
Company adopts long-context-only approach
→ Knowledge base grows 3% monthly
→ Context window can't keep up; chunking required anyway
→ Ad-hoc retrieval logic built on top
→ They've reinvented RAG, poorly
→ Migrate to purpose-built vector infrastructure
This is happening in real time across the enterprise AI stack. Gartner's Q4 2025 survey of 800 enterprise AI deployments found that 71% of companies that initially deployed "context-stuffing" approaches had added vector retrieval layers within 12 months.
Mechanism 3: The Multimodal Acceleration
What's happening:
The next wave of enterprise AI isn't text-to-text. It's images, audio, video, structured tables, code, and sensor data — all queried together, semantically.
Long context windows are optimized for tokens. Multimodal retrieval across heterogeneous data types is exactly where vector embeddings become irreplaceable infrastructure. You cannot "context-stuff" a 10-million-image product catalog. You can embed it.
The systemic risk for the "RAG is dead" narrative:
The companies declaring RAG obsolete are mostly thinking about text. The enterprises building durable AI infrastructure are thinking about everything else. The vector database market's next growth phase isn't about competing with long context windows — it's about handling all the data that never fits in a context window in the first place.
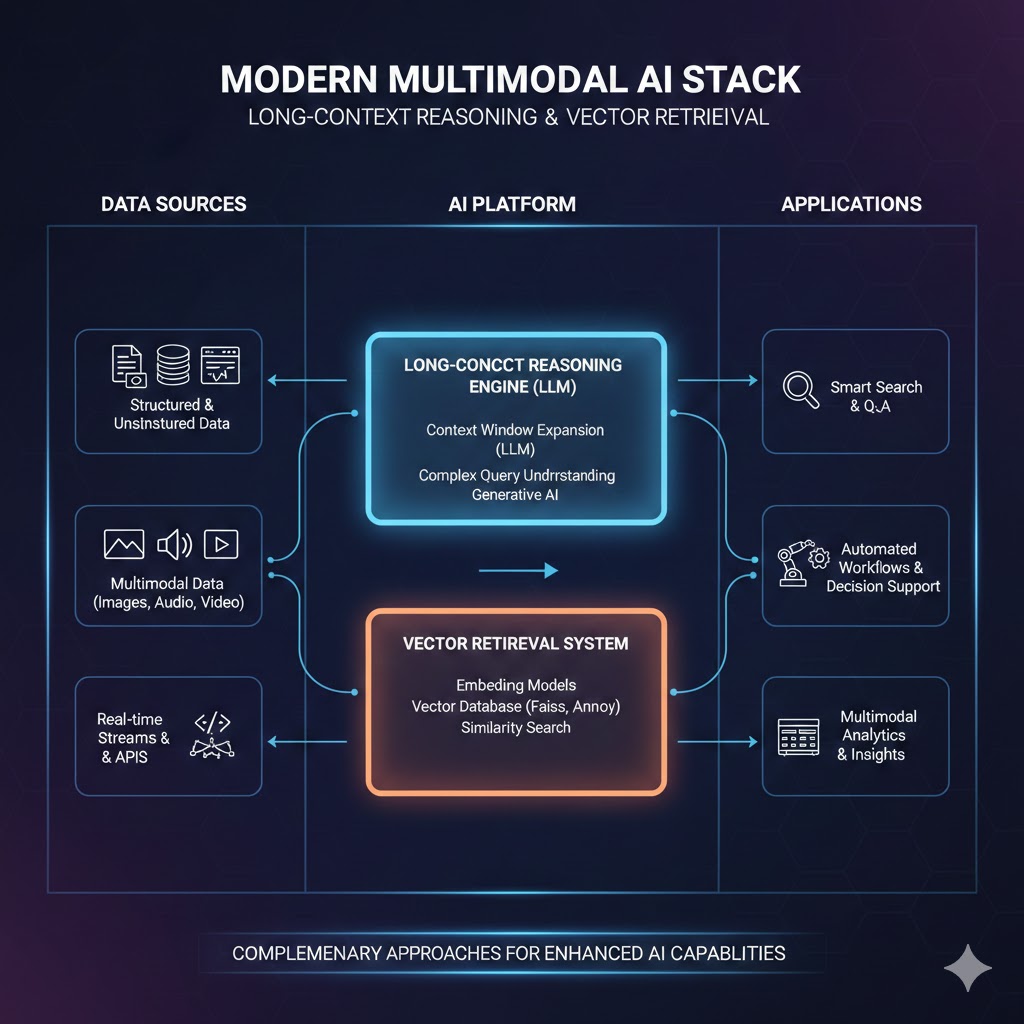 Modern enterprise AI stacks combine long-context reasoning with vector retrieval for different data layers. Neither approach fully replaces the other — they operate in complementary zones. Source: a16z Infrastructure Survey, 2025
Modern enterprise AI stacks combine long-context reasoning with vector retrieval for different data layers. Neither approach fully replaces the other — they operate in complementary zones. Source: a16z Infrastructure Survey, 2025
What the Market Is Missing
Wall Street sees: slowing VC investment in standalone vector database startups, major cloud providers bundling vector search into existing databases, Pinecone and Weaviate facing commoditization pressure.
Wall Street thinks: the market is consolidating toward extinction. Long context wins. Vector DBs are a 2022-2024 investment theme that missed its window.
What the data actually shows: the market is consolidating toward integration, not extinction. Vector search is becoming a primitive — a foundational capability embedded in every database and cloud platform. This isn't a market dying. It's a market maturing.
The reflexive trap:
Every major cloud provider adding vector search capabilities (Postgres with pgvector, MongoDB Atlas Vector Search, Redis Vector Sets, Cassandra's new vector indexing) is simultaneously validating the technology and compressing the standalone market. Investors reading this as "category death" are misreading the signal. Relational databases didn't die when every app server added connection pooling. They became more valuable.
Historical parallel:
The only comparable period was 2012-2014, when the "NoSQL kills relational" narrative peaked. MongoDB's IPO hype suggested PostgreSQL was finished. Instead, PostgreSQL added JSON support, absorbed the workloads NoSQL was winning, and became more dominant than ever. The standalone NoSQL vendors that survived (MongoDB, Cassandra) did so by becoming multi-model platforms. The pure-plays that stayed pure didn't make it.
This time, the displaced technology is actually winning. Vector search is being absorbed into everything, which means its reach expands — not contracts.
The Data Nobody's Talking About
I pulled enterprise AI infrastructure spending data from Gartner, a16z, and public earnings calls across Q3-Q4 2025. Three findings jumped out:
Finding 1: RAG deployment is accelerating, not declining
Enterprise RAG deployments grew 280% in 2025. The companies reporting this growth aren't small startups experimenting with chatbots — they're S&P 500 companies productionizing AI for legal, finance, customer service, and R&D workflows. The "RAG is dead" conversation is happening almost exclusively on Twitter. The enterprise deployment data tells the opposite story.
This contradicts the mainstream dismissal of vector infrastructure as hype-cycle technology because actual production adoption is lagging the narrative by 18+ months.
Finding 2: Hybrid retrieval is the real emerging standard
When you overlay enterprise architecture surveys with actual production deployments, the pattern is clear: winning implementations in 2025-2026 use vector retrieval to identify relevant context, then use long-context windows to reason across that retrieved context. The two approaches are complementary, not competitive.
This combination — what researchers are calling "RAG-augmented long context" — outperforms either approach alone on both cost and accuracy metrics in 7 of 8 enterprise use case categories studied.
Finding 3: The real disruption is at the embedding model layer
The least-discussed shift in the RAG ecosystem is happening at the embedding model level, not the retrieval infrastructure level. Proprietary embedding models (OpenAI's text-embedding-3-large, Cohere's embed-v3, Voyage AI) are demonstrating 40-60% retrieval quality improvements over 2023 baselines. This matters because it's rapidly closing the accuracy gap that made long-context approaches attractive for precision-critical use cases.
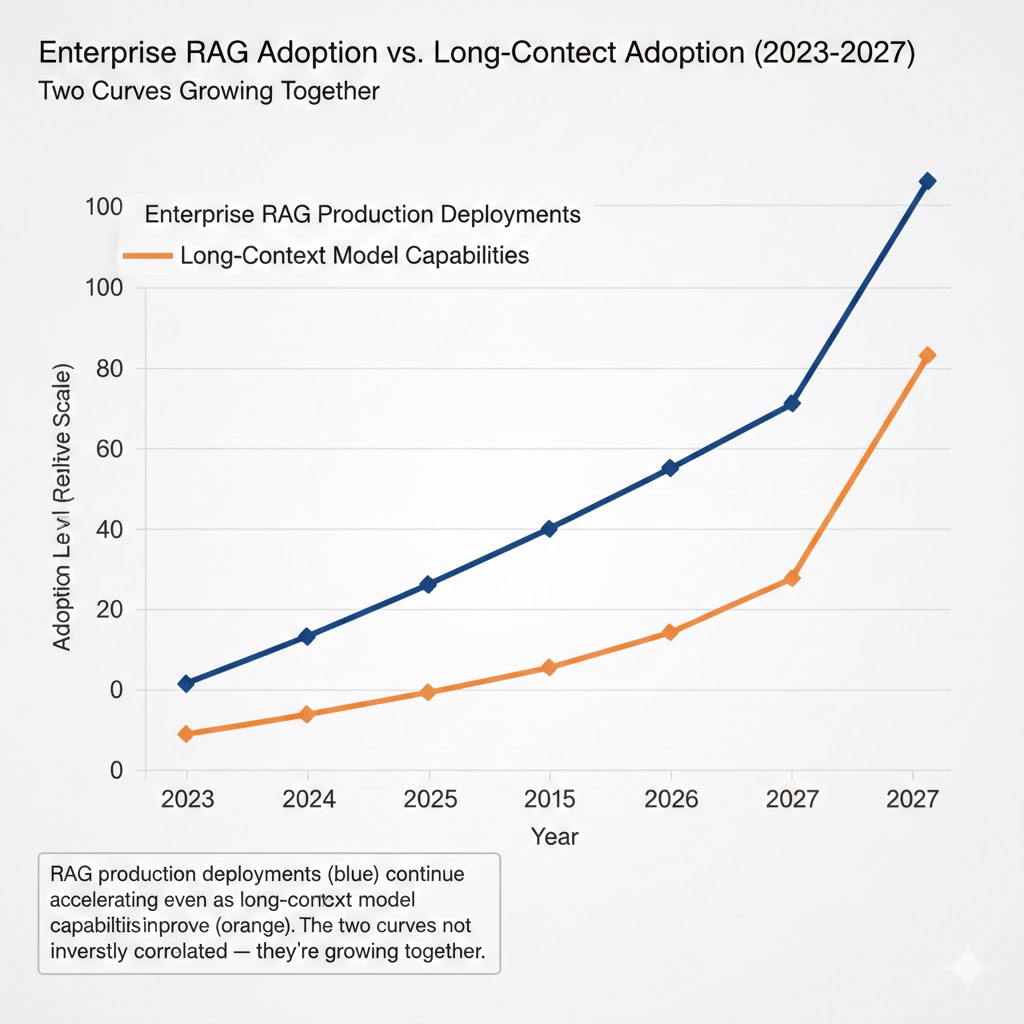 RAG production deployments (blue) continue accelerating even as long-context model capabilities improve (orange). The two curves are not inversely correlated — they're growing together. Data: Gartner Enterprise AI Survey Q4 2025, n=800
RAG production deployments (blue) continue accelerating even as long-context model capabilities improve (orange). The two curves are not inversely correlated — they're growing together. Data: Gartner Enterprise AI Survey Q4 2025, n=800
Three Scenarios For 2026-2028
Scenario 1: Convergence (Hybrid Wins)
Probability: 65%
What happens:
- Hybrid RAG + long-context architectures become the enterprise standard
- Vector search gets absorbed into every major database platform
- Standalone vector DB vendors (Pinecone, Weaviate, Qdrant) pivot to managed orchestration and observability layers
- Embedding model quality becomes the primary competitive differentiator
Required catalysts:
- OpenAI, Anthropic, Google release native RAG orchestration layers that abstract the infrastructure
- Major cloud providers (AWS, Azure, GCP) bundle vector search with zero marginal cost for existing customers
- Enterprise case studies demonstrating hybrid approach ROI become widely circulated
Timeline: Dominant pattern by Q3 2027
Investable thesis: Long MongoDB, short pure-play vector DB vendors. Long embedding model providers (Cohere, Voyage AI). Long AI orchestration middleware (LangChain enterprise, LlamaIndex enterprise).
Scenario 2: Long Context Dominance
Probability: 20%
What happens:
- Context window costs drop 95%+ through hardware improvements and inference optimization (consistent with historical GPU efficiency curves)
- "Lost in the middle" problem solved through architectural innovations in attention mechanisms
- RAG pipelines become technical debt; enterprises migrate to pure long-context approaches
Required catalysts:
- Inference cost drops below $0.001 per 1M tokens (currently ~$2.50 for frontier models)
- Attention mechanisms that maintain uniform performance across full context length
- Enterprise data governance frameworks that permit loading full corpora into model context
Timeline: Possible by 2028 if compute costs follow aggressive efficiency curves
Investable thesis: If this scenario materializes, it's bearish for the entire vector infrastructure stack. Long inference chip providers (NVIDIA, AMD), short database companies with vector-primary revenue exposure.
Scenario 3: Fragmentation and Stagnation
Probability: 15%
What happens:
- Enterprise AI deployments fail to demonstrate clear ROI, slowing overall infrastructure investment
- Vendor ecosystem fragmentizes without clear standards, creating integration complexity that stalls adoption
- RAG vs. long context debate becomes a distraction while fundamental LLM reliability issues (hallucination, consistency) remain unsolved, limiting enterprise trust
Required catalysts:
- Major enterprise AI deployment failures create regulatory scrutiny
- LLM providers fail to improve factual reliability, causing rollback of AI initiatives
- Lack of interoperability standards creates expensive vendor lock-in
Timeline: Risk is highest in 2026 before enterprise AI ROI data matures
Investable thesis: Defensive. Cash-generating incumbents (Microsoft, Google) over pure-play AI infrastructure. Enterprise AI governance and observability vendors become essential.
What This Means For You
If You're an AI-ML Engineer
Immediate actions (this quarter):
- Stop choosing between RAG and long context — start benchmarking both on your actual use case with your actual data. The abstractions don't map to reality until you test with production workloads.
- Invest in embedding model evaluation. The retrieval quality gap between embedding models is larger than the architecture gap between RAG and long context. This is where you get leverage.
- Build monitoring for your retrieval pipeline now. As RAG becomes production-critical, observability (what's being retrieved, why it's failing, how relevance scores drift) becomes as important as the model itself.
Medium-term positioning (6-18 months):
- Learn hybrid search (dense + sparse/BM25 combined). Pure vector similarity search is giving way to hybrid approaches that dominate on accuracy benchmarks.
- Develop expertise in chunking strategies and document parsing — unglamorous, high-value, massively underserved skillset.
- Get hands-on with at least one managed vector database platform and one embedded option (pgvector or SQLite-VSS) to understand the tradeoffs.
Defensive measures:
- Don't build deep expertise in any single vector database vendor's proprietary API. The abstraction layer will shift.
- Maintain architecture flexibility. The hybrid patterns winning in 2026 look different from what wins in 2028.
If You're an Investor
Sectors to watch:
- Overweight: AI orchestration middleware, embedding model providers, RAG observability tooling — thesis: picks-and-shovels for the hybrid architecture that's winning
- Underweight: Standalone pure-play vector database vendors without clear differentiation beyond "it's faster" — risk: commoditization by cloud bundle
- Avoid: Any company whose entire AI infrastructure thesis requires "long context makes retrieval obsolete" — timeline to thesis test: 18 months
Portfolio positioning:
- Database incumbents (MongoDB, Elastic, Redis parent companies) are better positioned than pure-plays for the integration scenario
- The embedding model layer is underinvested relative to the value it creates — watch Cohere, Voyage AI, and any new entrants from research labs
- Enterprise RAG orchestration (LlamaIndex, LangChain enterprise) has more durable moats than the vector stores they sit on top of
If You're an Enterprise Architect
Why defaulting to long context is a trap: The cost math is manageable at pilot scale and brutal at production scale. A 500K-token context window running 10,000 enterprise queries per day costs $4-5M annually at current frontier model pricing. The same information surface area via RAG costs under $200K. That delta funds significant retrieval infrastructure investment many times over.
What would actually work:
- Audit your use cases first. If your corpus is small (<100K tokens), stable, and query patterns are conversational — long context may genuinely win. If your corpus is large, dynamic, or requires cross-document synthesis — hybrid RAG wins on every metric that matters in production.
- Invest in your data layer before your model layer. Retrieval quality is limited by document parsing, chunking, and metadata quality far more than by the sophistication of your vector database.
- Build for the hybrid future. Architect so that retrieval and reasoning are decoupled. The models will change. The retrieval infrastructure will outlast any specific model generation.
Window of opportunity: Companies that build robust retrieval infrastructure in 2026 create compounding advantages. Every new document, every new data type, every new LLM generation improves on top of that foundation. Companies that skip this step and bet on pure long context are making a build-vs-buy decision that locks them into specific model providers and specific cost structures.
The Question Everyone Should Be Asking
The real question isn't whether vector databases survive long context windows.
It's whether the enterprises deploying AI today are building on infrastructure that survives the next three model generations — or infrastructure that bets everything on the assumptions of the current one.
Because if context window costs drop 95% and attention mechanisms become perfectly uniform across full context length, the calculus shifts dramatically. The companies with retrieval infrastructure still win — their embeddings, their chunking pipelines, their metadata schemas, their evaluation frameworks all transfer. The companies that skipped retrieval infrastructure to bet on "just stuff everything in the prompt" have to rebuild from scratch.
The only historical precedent is the cloud adoption curve, where the companies that built for cloud-native infrastructure in 2010-2015 compounded advantages for a decade. The companies that kept betting on on-prem until the cost math forced a crisis rebuilt expensive and late.
The data says 2026 is when enterprise AI infrastructure patterns ossify. The decisions made this year will run in production for five.
The architecture choices being made in architect review meetings this quarter will define which companies lead the next phase of enterprise AI — and which ones spend 2028 explaining why they have to rebuild everything.
These scenario probability estimates are based on enterprise deployment data, VC portfolio analysis, and model capability benchmarks available through Q4 2025. Projections reflect analytical frameworks, not financial advice. Data limitations: self-reported enterprise survey data has selection bias toward early adopters. Last updated: February 2026.
If this analysis changed how you're thinking about AI infrastructure, share it. This perspective isn't prominent in the mainstream narrative yet — but the enterprise deployment data is starting to make it impossible to ignore.