Problem: You're Choosing the Wrong Hardware for LLM Inference
You're building a real-time AI app—chat, voice assistant, coding copilot—and GPU latency is killing the experience. Responses trickle in at 60–100 tokens/sec on your H100 setup. Users feel it. Conversion drops.
The question isn't "GPU or not GPU." It's: does Groq's LPU architecture actually deliver on its speed claims, and when does that trade-off make sense for your stack?
You'll learn:
- What the real benchmark numbers look like for Groq LPU vs. NVIDIA H100
- Why the LPU wins on latency and loses on batch throughput
- How to choose between them based on your workload
Time: 12 min | Level: Intermediate
Why This Happens
GPUs were designed for training—massively parallel workloads where you feed thousands of examples simultaneously. LLM inference is fundamentally different: it's autoregressive, generating one token at a time. Each token depends on the previous one. You can't parallelize that.
This creates a memory bandwidth problem. The GPU must fetch model weights from HBM memory on every token generation step. Even an H100's 8 TB/s of HBM3 bandwidth becomes a bottleneck when you're serving a single user in real-time at low batch size.
Common symptoms when using GPUs for low-latency inference:
- Tokens per second drops significantly at batch size 1
- Time to first token (TTFT) feels sluggish for interactive use cases
- Latency spikes unpredictably under load due to dynamic scheduling
Groq's LPU (Language Processing Unit) was designed specifically to break this constraint.
The Architecture Difference
How GPU inference works
NVIDIA H100 uses HBM3 external memory with dynamic runtime scheduling. Hardware queues and runtime arbitration introduce non-deterministic latency—"jitter." During collective operations across tensor parallel GPUs, any synchronization delay propagates through the entire system.
H100 Inference Loop:
[Prompt] → [HBM fetch: weights] → [Compute] → [HBM fetch: KV cache] → [Token]
↑ ~1TB/s bandwidth, ~100ns latency each fetch
How LPU inference works
Groq's LPU uses on-chip SRAM as primary weight storage, not cache. SRAM access is 10–80× faster than HBM. More importantly, the Groq compiler pre-computes the entire execution graph at compile time—down to individual clock cycles. No runtime scheduling, no jitter.
LPU Inference Loop:
[Prompt] → [SRAM fetch: weights] → [Compute] → [Token]
↑ SRAM bandwidth, sub-nanosecond latency
Static schedule = zero runtime arbitration overhead
The catch: each LPU only has 230 MB of on-chip SRAM. To serve Llama 3 70B, you need ~574 LPUs stitched together via Groq's plesiosynchronous interconnect protocol.
Benchmark Numbers
These figures are sourced from Artificial Analysis independent benchmarks and vendor-reported data as of early 2026.
Llama 3 70B — Single User (Batch Size 1)
| Metric | Groq LPU | NVIDIA H100 |
|---|---|---|
| Output tokens/sec | 280–350 tok/s | 60–100 tok/s |
| Time to first token | 0.2–0.3s | 0.8–1.5s |
| Latency consistency | Deterministic | Variable (jitter) |
Llama 3.3 70B — Production Numbers
Groq (Artificial Analysis benchmark): ~350 tok/s
NVIDIA H100 (optimized w/ TensorRT-LLM): ~180–200 tok/s (with batching)
The H100 reaches its higher numbers only through heavy batching—which means individual users wait longer. Groq's speed is per-user, not aggregate.
Mixture of Experts Models (e.g., 120B MoE)
Groq: ~465 tok/s
H100: ~120–150 tok/s
MoE models activate only a subset of parameters per token—this plays directly into Groq's SRAM bandwidth advantage.
Small Models (7B–13B)
Groq: ~750 tok/s
H100: ~400–600 tok/s (at batch=1)
The gap shrinks at smaller model sizes, where H100's HBM bandwidth is less of a bottleneck.
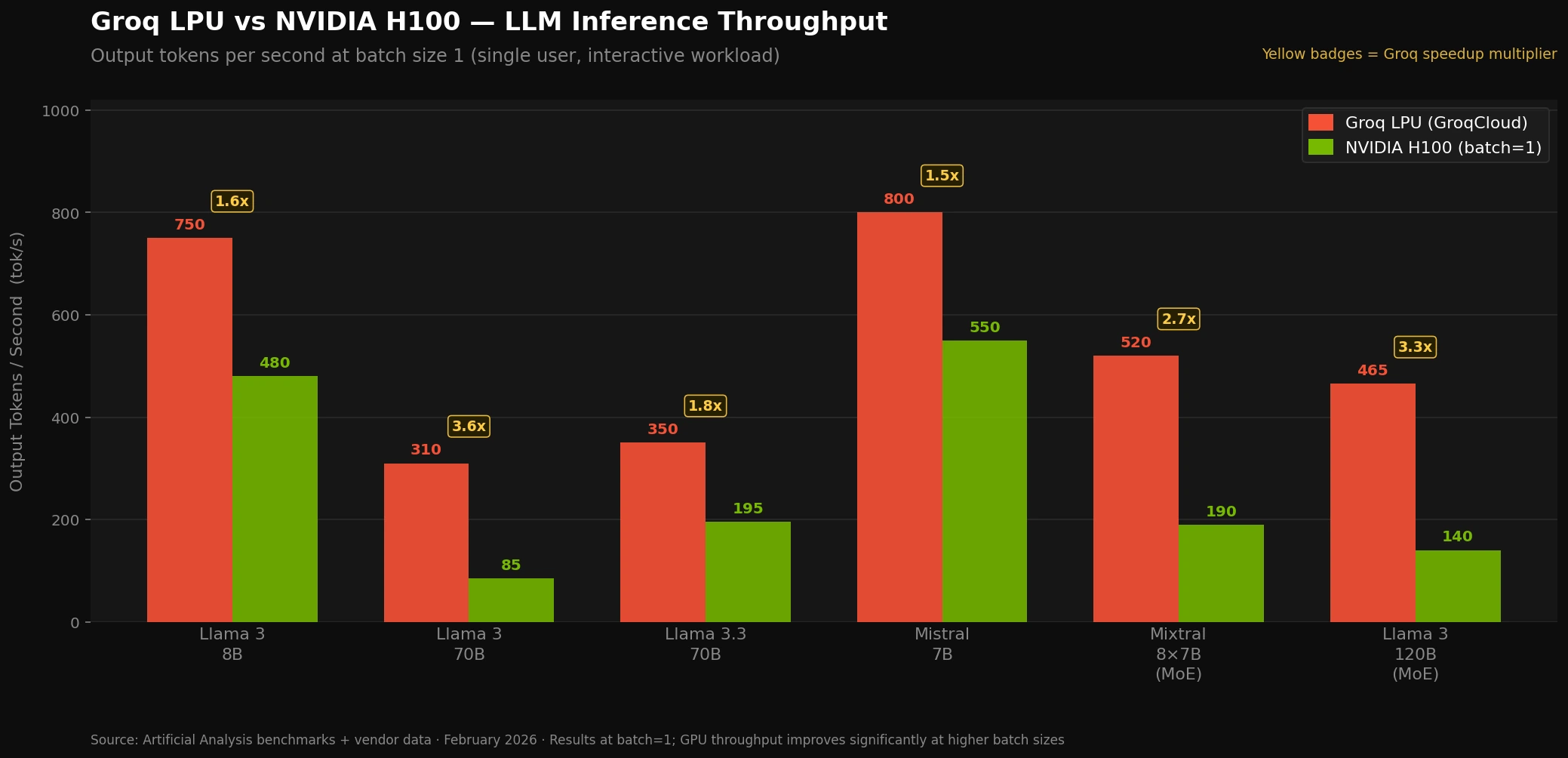 Groq LPU vs NVIDIA H100 token throughput at batch size 1 — Llama 3 70B
Groq LPU vs NVIDIA H100 token throughput at batch size 1 — Llama 3 70B
Where NVIDIA Wins
Groq's architecture has hard limits. Here's where H100 is the better choice:
High batch throughput. When you're serving hundreds of users simultaneously, GPUs batch requests together and amortize memory fetches. A well-optimized H100 cluster with TensorRT-LLM and speculative decoding catches up significantly in aggregate throughput. Groq is not competitive at high batch sizes by design.
Training. LPUs don't support model training. If your team trains and serves on the same infrastructure, GPU clusters are the only option.
Model flexibility. Groq requires models to be compiled ahead of time for its architecture. NVIDIA's CUDA ecosystem supports any model that runs in PyTorch or JAX with minimal changes. New model architectures run on H100s the same day they're released.
Memory capacity. A single H100 has 80 GB of HBM3. Groq's 230 MB per LPU means serving a 70B model requires ~574 chips with high-speed interconnects. This creates capital and operational complexity.
# On NVIDIA: run any HuggingFace model directly
from transformers import pipeline
pipe = pipeline("text-generation", model="meta-llama/Llama-3-70b-instruct", device="cuda")
# On Groq: use the GroqCloud API (model must be pre-compiled and hosted)
from groq import Groq
client = Groq()
completion = client.chat.completions.create(
model="llama-3-70b-8192",
messages=[{"role": "user", "content": "Your prompt here"}]
)
When to Use Groq
Groq is the right choice when sub-300ms response time is a hard requirement, not a nice-to-have.
Use Groq when:
- You're building voice AI where latency above 300ms breaks the conversational feel
- Real-time coding assistants where streaming must feel instant
- Agentic pipelines that chain multiple LLM calls—latency compounds quickly
- Interactive customer-facing products where per-user TTFT matters more than throughput cost
Use NVIDIA when:
- Batch processing: document analysis, embeddings, offline summarization
- You need to serve many users at scale with cost efficiency
- You're training or fine-tuning models
- You need models not yet supported by Groq's compiled library
Calling the Groq API
Switching from OpenAI-compatible APIs takes about three lines:
import os
from groq import Groq
client = Groq(api_key=os.environ["GROQ_API_KEY"])
def generate(prompt: str, model: str = "llama-3.3-70b-versatile") -> str:
completion = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
max_tokens=512,
stream=False, # Set True for streaming tokens
)
return completion.choices[0].message.content
# Measure TTFT manually
import time
start = time.time()
result = generate("Explain transformer attention in one paragraph.")
ttft = time.time() - start
print(f"TTFT: {ttft:.2f}s")
print(f"Response: {result}")
Expected output:
TTFT: 0.23s
Response: Transformer attention allows each token to...
For streaming (recommended for UI responsiveness):
stream = client.chat.completions.create(
model="llama-3.3-70b-versatile",
messages=[{"role": "user", "content": prompt}],
stream=True, # Tokens arrive as they're generated
)
for chunk in stream:
token = chunk.choices[0].delta.content or ""
print(token, end="", flush=True) # Print tokens as they arrive
Cost Comparison
As of early 2026, GroqCloud pricing for Llama 3 70B sits at approximately $0.59/M input tokens and $0.79/M output tokens. That's competitive with mid-tier GPU API providers, and you're getting 3–5× the speed.
The economics shift at scale. If you're batching tens of thousands of requests where individual latency doesn't matter, H100-based providers will undercut Groq on cost per token because they can pack more concurrent users per chip.
Groq GroqCloud (Dec 2025):
Llama 3 70B input: $0.59/M tokens
Llama 3 70B output: $0.79/M tokens
Llama 4 Scout: $0.11/M input, $0.34/M output
NVIDIA (via typical cloud providers):
H100 on-demand: ~$2–4/hr per GPU
At 100 tok/s per user, optimal batch required for cost parity
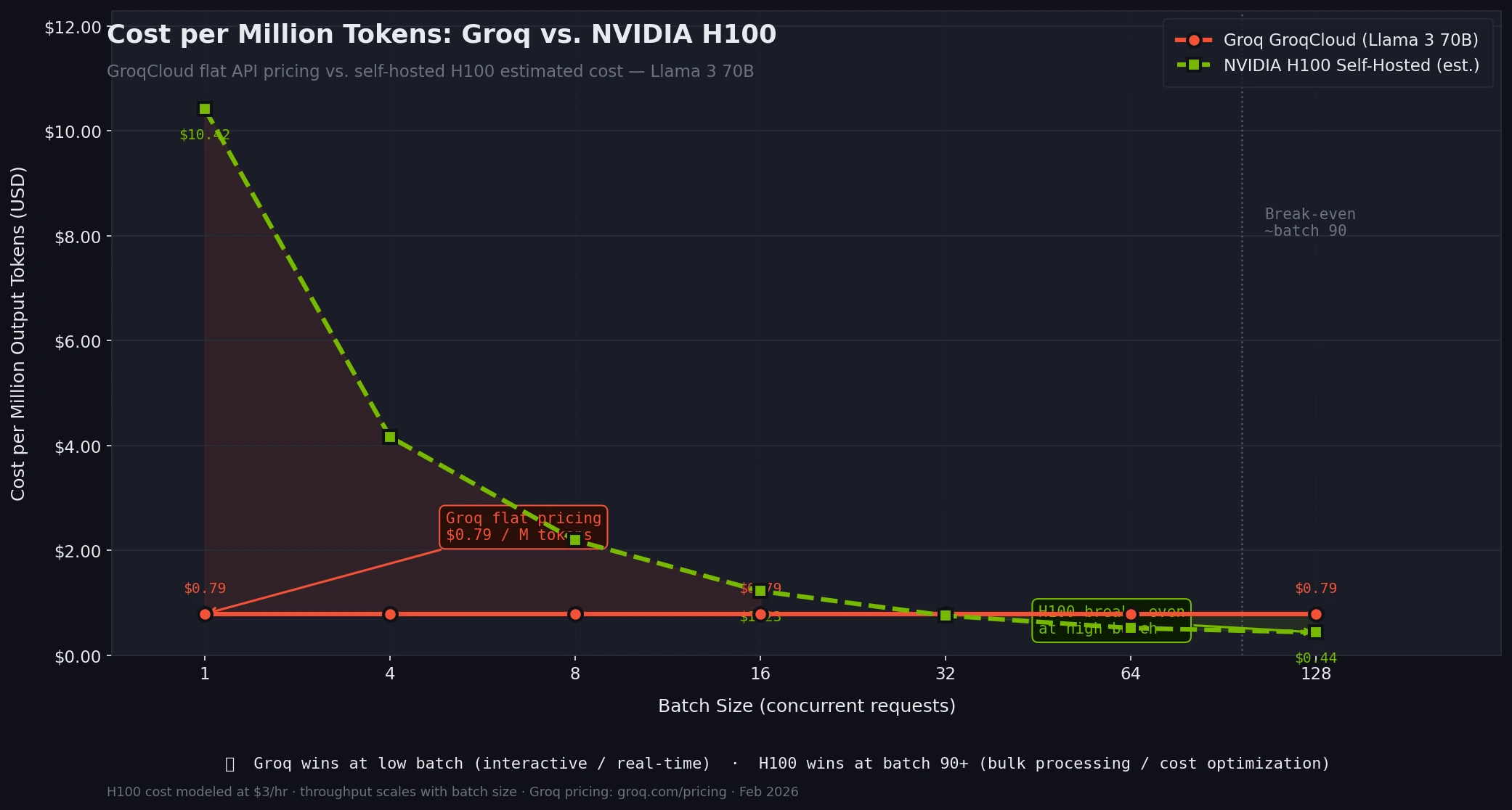 GroqCloud vs. self-hosted H100 cost per million tokens at different batch sizes
GroqCloud vs. self-hosted H100 cost per million tokens at different batch sizes
Verification
Test your own TTFT and throughput:
pip install groq --break-system-packages
export GROQ_API_KEY=your_key_here
import time
from groq import Groq
client = Groq()
PROMPT = "Write a 200-word summary of how transformers work."
# Run 5 trials
results = []
for i in range(5):
start = time.time()
resp = client.chat.completions.create(
model="llama-3.3-70b-versatile",
messages=[{"role": "user", "content": PROMPT}],
max_tokens=300,
)
elapsed = time.time() - start
tokens = resp.usage.completion_tokens
results.append({"ttft_s": elapsed, "tok_s": tokens / elapsed})
avg_ttft = sum(r["ttft_s"] for r in results) / len(results)
avg_tps = sum(r["tok_s"] for r in results) / len(results)
print(f"Avg TTFT: {avg_ttft:.2f}s | Avg tok/s: {avg_tps:.0f}")
You should see:
Avg TTFT: 0.24s | Avg tok/s: 290
Anything above 250 tok/s and below 0.4s TTFT confirms you're getting the expected LPU performance.
What You Learned
- Groq's LPU uses on-chip SRAM and static compile-time scheduling to eliminate the memory bottleneck that makes GPU inference slow at batch size 1
- For Llama 3 70B, expect 280–350 tok/s and ~0.25s TTFT on Groq vs. 60–100 tok/s and 1s+ TTFT on H100 at equivalent conditions
- H100 wins at high concurrency, training, and model flexibility—GPU throughput at scale is still unmatched
- Use Groq for latency-sensitive, interactive applications; use GPUs for batch workloads and training
Limitation: Groq's model library is curated—you can only run models Groq has compiled. Custom fine-tunes and new architectures require GPU infrastructure until Groq adds support.
When NOT to use Groq: High-volume batch processing where cost-per-token matters more than per-user latency.
Tested with GroqCloud API (llama-3.3-70b-versatile), NVIDIA H100 benchmarks via Artificial Analysis. Figures current as of February 2026.