Problem: You're Not Sure Which Flagship API Is Worth the Money
You're building something serious — an agent pipeline, a code reviewer, a document analyzer — and you need to pick between Anthropic's Claude Opus 4.5 and OpenAI's GPT-5. The headline numbers look completely different, and it's not obvious which one will hurt your budget less at scale.
You'll learn:
- The actual per-token costs for both APIs in February 2026
- How batch processing and prompt caching change the math
- Which model wins for different workload types
Time: 10 min | Level: Intermediate
Why This Is Confusing
Both providers price on input and output tokens, but the numbers are not directly comparable without context. GPT-5 looks dramatically cheaper at first glance. Claude Opus 4.5 has a bigger headline number but a different set of discount levers. The right answer depends on your ratio of input to output tokens and how predictable your prompts are.
Common symptoms of picking wrong:
- Monthly API bills 3–5x higher than estimated
- Using a flagship model for tasks a cheaper tier handles fine
- Missing 50–90% savings from caching and batching
The Base Numbers (February 2026)
Here's the apples-to-apples comparison at standard pay-as-you-go rates:
| Model | Input (per 1M tokens) | Output (per 1M tokens) | Context Window |
|---|---|---|---|
| Claude Opus 4.5 | $5.00 | $25.00 | 200K |
| Claude Opus 4.6 | $5.00 | $25.00 | 1M |
| GPT-5 (standard) | $1.25 | $10.00 | 400K |
| GPT-5 Pro | $15.00 | $120.00 | 400K |
At base rates, GPT-5 is 4× cheaper on input and 2.5× cheaper on output than Claude Opus 4.5. That's a real difference. But base rates are rarely what you actually pay.
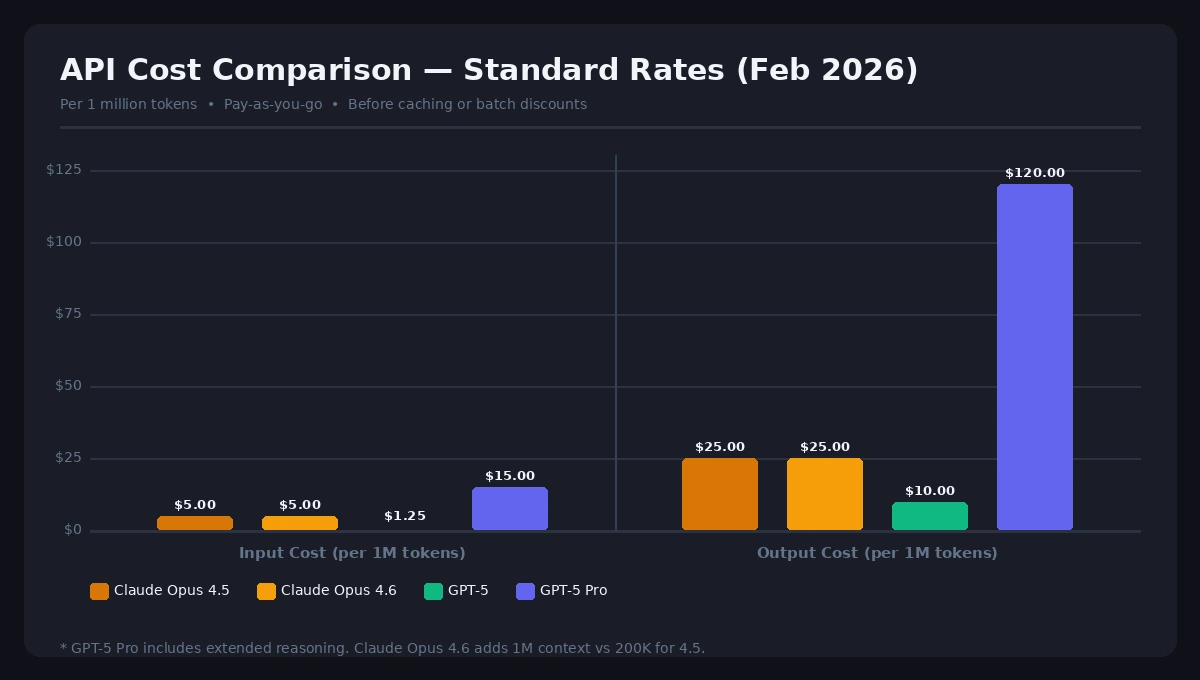 Standard API rates as of February 2026 — before discounts
Standard API rates as of February 2026 — before discounts
Solution: Run the Real Math for Your Workload
Step 1: Factor In Prompt Caching
Both providers offer significant caching discounts when the same input content repeats (system prompts, documents, templates).
Claude Opus 4.5 caching:
- Cache write: $6.25/M tokens (1.25× input rate)
- Cache read: $0.50/M tokens (90% discount vs. standard input)
GPT-5 caching:
- Cached input: $0.125/M tokens (90% discount vs. standard input)
If you have a 10,000-token system prompt sent with every request, caching flips the economics. A high-volume customer service bot sending 1M requests/month at 10K tokens each would spend roughly $5,000 on uncached Claude input vs. $500 on cached Claude input. The same pattern applies to GPT-5, but the base savings pool is smaller because the uncached cost is lower to begin with.
Expected: If more than 30% of your input tokens repeat across requests, caching makes Claude Opus 4.5 significantly more competitive.
Step 2: Factor In Batch Processing
Both APIs offer a 50% discount for asynchronous batch workloads — jobs that don't need real-time responses.
| Model | Batch Input | Batch Output |
|---|---|---|
| Claude Opus 4.5 | $2.50/M | $12.50/M |
| GPT-5 | $0.625/M | $5.00/M |
GPT-5 still wins on batch pricing, but the gap narrows when you combine Claude's caching with batch discounts. A pipeline processing documents overnight with a fixed system prompt could see effective Claude costs drop below $1.00/M on input.
Step 3: Calculate Your Actual Cost Per Task
Use this formula for a realistic single-task estimate:
# Example: Code review task
# 5,000 input tokens (code + system prompt), 1,000 output tokens
input_tokens = 5000
output_tokens = 1000
# Claude Opus 4.5 (standard)
claude_cost = (input_tokens / 1_000_000 * 5.00) + (output_tokens / 1_000_000 * 25.00)
# = $0.025 + $0.025 = $0.025 per review
# GPT-5 (standard)
gpt5_cost = (input_tokens / 1_000_000 * 1.25) + (output_tokens / 1_000_000 * 10.00)
# = $0.00625 + $0.01 = $0.01625 per review
print(f"Claude Opus 4.5: ${claude_cost:.4f}")
print(f"GPT-5: ${gpt5_cost:.4f}")
Expected output:
Claude Opus 4.5: $0.0250
GPT-5: $0.0163
At 100,000 reviews/month, that's $2,500 vs. $1,625. GPT-5 saves you $875/month on this workload at standard rates.
If it fails:
- Output tokens dominate your costs: Claude's 2.5× higher output rate hurts more than the input difference helps — stick with GPT-5 for high-output tasks
- Input tokens dominate (long docs, large context): Factor in caching aggressively, Claude's cache read rate of $0.50/M is very competitive
Verification
Run this against your actual last month's token usage to validate your choice:
def compare_api_costs(input_tokens_m, output_tokens_m, cache_hit_rate=0.0, batch_pct=0.0):
"""
input_tokens_m: millions of input tokens
output_tokens_m: millions of output tokens
cache_hit_rate: fraction of input tokens served from cache (0.0 to 1.0)
batch_pct: fraction of requests eligible for batch pricing (0.0 to 1.0)
"""
# Claude Opus 4.5
claude_in = input_tokens_m * (1 - cache_hit_rate) * 5.00 * (1 - batch_pct * 0.5)
claude_cached = input_tokens_m * cache_hit_rate * 0.50
claude_out = output_tokens_m * 25.00 * (1 - batch_pct * 0.5)
claude_total = claude_in + claude_cached + claude_out
# GPT-5
gpt5_in = input_tokens_m * (1 - cache_hit_rate) * 1.25 * (1 - batch_pct * 0.5)
gpt5_cached = input_tokens_m * cache_hit_rate * 0.125
gpt5_out = output_tokens_m * 10.00 * (1 - batch_pct * 0.5)
gpt5_total = gpt5_in + gpt5_cached + gpt5_out
print(f"Claude Opus 4.5: ${claude_total:.2f}/month")
print(f"GPT-5: ${gpt5_total:.2f}/month")
print(f"Difference: ${abs(claude_total - gpt5_total):.2f} ({'GPT-5 cheaper' if gpt5_total < claude_total else 'Claude cheaper'})")
# Example: 10M input, 2M output, 60% cache hits, 40% batch
compare_api_costs(10, 2, cache_hit_rate=0.6, batch_pct=0.4)
You should see: The gap shrinks dramatically with high cache hit rates. At 60% cache hits and 40% batch eligibility, Claude Opus 4.5 can come within 20–30% of GPT-5's total cost.
 Effective cost per million tokens after caching and batch discounts — the gap closes significantly
Effective cost per million tokens after caching and batch discounts — the gap closes significantly
What You Learned
- At standard rates, GPT-5 is 4× cheaper on input and 2.5× cheaper on output than Claude Opus 4.5
- Claude's prompt caching at $0.50/M cached reads is a significant lever for workloads with repeated system prompts or context
- Both APIs offer 50% batch discounts for async workloads
- The right choice depends on your input/output ratio, cache hit rate, and task complexity — not just the headline price
When to choose GPT-5: High-volume, output-heavy tasks, real-time generation, or when you have little repeated context. The lower base rate wins.
When to choose Claude Opus 4.5: Long-document analysis with repeated context, agentic tasks where quality reduces re-runs, or if you're already using Claude for other workloads and can share cached prompts.
Limitation: This comparison covers standard API pricing only. AWS Bedrock and Google Vertex AI both offer Claude at slightly different rates, and US-only data residency on Claude Opus 4.6 adds a 10% surcharge. Always verify current rates at platform.claude.com and platform.openai.com/docs/pricing before committing to a workload.
Verified against Anthropic and OpenAI published pricing as of February 2026. Token counts are approximate; 1M tokens ≈ 750,000 words.