Problem: LLM Output Regressions Ship Without Detection
You change a prompt, swap a model version, or update a temperature setting. Tests pass. You deploy. Then users report broken outputs — hallucinations that weren't there before, formatting regressions, or accuracy drops on edge cases.
Standard unit tests don't catch LLM regressions because outputs are probabilistic and fuzzy. You need eval-based gates that run on every PR.
You'll learn:
- How to create a LangSmith dataset and evaluator for regression testing
- How to run LangSmith evals inside a GitHub Actions workflow
- How to fail a CI pipeline when eval scores drop below threshold
Time: 25 min | Difficulty: Intermediate
Why LLM Regression Testing Is Different
Unit tests assert output == expected. LLM outputs are never identical across runs — they're semantically correct or incorrect.
LangSmith solves this with datasets + evaluators:
- Dataset: a fixed set of
(input, reference output)pairs - Evaluator: a function (or LLM-as-judge) that scores each run against the reference
- Threshold: CI fails if average score drops below your acceptable baseline
PR opened
│
▼
GitHub Actions triggers eval run
│
▼
LangSmith runs your chain against dataset (e.g., 50 examples)
│
▼
Evaluator scores each output (0.0 – 1.0)
│
▼
Pass if avg score ≥ 0.85, else fail the PR
Setup
Step 1: Install Dependencies
# Use uv for fast installs (Python 3.11+)
uv add langsmith langchain-openai python-dotenv
# Or pip
pip install langsmith langchain-openai python-dotenv
Set your environment variables:
export LANGCHAIN_API_KEY="ls__your_key_here"
export LANGCHAIN_TRACING_V2=true
export OPENAI_API_KEY="sk-your_key_here"
Step 2: Create Your Evaluation Dataset
A dataset is the ground truth your chain is tested against. Create it once; it persists in LangSmith.
# scripts/create_dataset.py
from langsmith import Client
client = Client()
# Define your ground-truth examples
# Each example: input your chain receives + reference output to score against
examples = [
{
"input": {"question": "What is the capital of France?"},
"output": {"answer": "Paris"},
},
{
"input": {"question": "Summarize: 'The cat sat on the mat.'"},
"output": {"answer": "A cat rested on a mat."},
},
{
"input": {"question": "Translate to Spanish: 'Good morning'"},
"output": {"answer": "Buenos días"},
},
# Add 20–50 examples covering your real use cases
]
dataset_name = "qa-regression-v1"
# Idempotent: skip if dataset already exists
existing = [d.name for d in client.list_datasets()]
if dataset_name not in existing:
dataset = client.create_dataset(dataset_name, description="QA regression suite")
client.create_examples(
inputs=[e["input"] for e in examples],
outputs=[e["output"] for e in examples],
dataset_id=dataset.id,
)
print(f"Created dataset '{dataset_name}' with {len(examples)} examples")
else:
print(f"Dataset '{dataset_name}' already exists — skipping creation")
python scripts/create_dataset.py
Expected output:
Created dataset 'qa-regression-v1' with 3 examples
Step 3: Define the Chain Under Test
This is the function LangSmith will call for each dataset example. Keep it identical to your production code.
# src/chain.py
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
def build_chain():
# Pull prompt from LangSmith Hub in production, or define inline for testing
prompt = ChatPromptTemplate.from_messages([
("system", "You are a helpful assistant. Answer concisely and accurately."),
("human", "{question}"),
])
model = ChatOpenAI(
model="gpt-4o-mini",
temperature=0, # temperature=0 for reproducible evals
)
return prompt | model | StrOutputParser()
def predict(inputs: dict) -> dict:
"""Adapter function — LangSmith calls this with each dataset input."""
chain = build_chain()
answer = chain.invoke({"question": inputs["question"]})
return {"answer": answer}
Step 4: Write the Evaluator
The evaluator scores each (prediction, reference) pair. Use an LLM-as-judge for semantic accuracy, or write a deterministic function for structured outputs.
# src/evaluators.py
from langsmith.schemas import Run, Example
from langchain_openai import ChatOpenAI
def semantic_accuracy(run: Run, example: Example) -> dict:
"""
LLM-as-judge: scores whether the prediction is semantically correct
relative to the reference. Returns a score between 0.0 and 1.0.
"""
prediction = run.outputs.get("answer", "")
reference = example.outputs.get("answer", "")
if not prediction:
return {"key": "semantic_accuracy", "score": 0.0}
judge = ChatOpenAI(model="gpt-4o-mini", temperature=0)
verdict = judge.invoke(
f"""You are an evaluation judge. Score whether the prediction matches
the reference answer semantically (not necessarily word-for-word).
Reference: {reference}
Prediction: {prediction}
Reply with ONLY a number between 0.0 (completely wrong) and 1.0 (correct).
No explanation."""
)
try:
score = float(verdict.content.strip())
score = max(0.0, min(1.0, score)) # clamp to [0, 1]
except ValueError:
score = 0.0
return {"key": "semantic_accuracy", "score": score}
def exact_match(run: Run, example: Example) -> dict:
"""
Deterministic evaluator for cases where exact output matters
(structured data, SQL, code snippets).
"""
prediction = run.outputs.get("answer", "").strip().lower()
reference = example.outputs.get("answer", "").strip().lower()
return {"key": "exact_match", "score": 1.0 if prediction == reference else 0.0}
Step 5: Create the Eval Runner Script
This is the script GitHub Actions will execute. It runs the eval and exits with a non-zero code if the score is below threshold — which fails the CI job.
# scripts/run_eval.py
import sys
from langsmith import Client
from langsmith.evaluation import evaluate
from src.chain import predict
from src.evaluators import semantic_accuracy
DATASET_NAME = "qa-regression-v1"
PASS_THRESHOLD = 0.85 # fail CI if average semantic_accuracy drops below this
client = Client()
print(f"Running eval against dataset: {DATASET_NAME}")
print(f"Pass threshold: {PASS_THRESHOLD}")
results = evaluate(
predict,
data=DATASET_NAME,
evaluators=[semantic_accuracy],
experiment_prefix="ci-regression", # groups runs in LangSmith UI by prefix
metadata={"trigger": "github-actions"},
)
# Compute average score across all examples
scores = [
r["evaluation_results"]["results"][0].score
for r in results
if r.get("evaluation_results")
]
if not scores:
print("ERROR: No scores returned — check evaluator output format")
sys.exit(1)
avg_score = sum(scores) / len(scores)
print(f"\nResults: {len(scores)} examples evaluated")
print(f"Average semantic_accuracy: {avg_score:.3f}")
if avg_score < PASS_THRESHOLD:
print(f"\nFAIL: {avg_score:.3f} is below threshold {PASS_THRESHOLD}")
print("Review regressions at: https://smith.langchain.com")
sys.exit(1) # non-zero exit fails the CI job
print(f"\nPASS: {avg_score:.3f} meets threshold {PASS_THRESHOLD}")
sys.exit(0)
Step 6: Add the GitHub Actions Workflow
# .github/workflows/llm-regression.yml
name: LLM Regression Tests
on:
pull_request:
branches: [main]
paths:
# Only run evals when prompt/chain code changes — not on README edits
- "src/**"
- "prompts/**"
- "scripts/run_eval.py"
jobs:
regression:
runs-on: ubuntu-latest
timeout-minutes: 15 # prevent runaway eval jobs from burning API budget
steps:
- uses: actions/checkout@v4
- uses: actions/setup-python@v5
with:
python-version: "3.12"
cache: "pip"
- name: Install dependencies
run: pip install langsmith langchain-openai python-dotenv
- name: Run LangSmith regression eval
env:
LANGCHAIN_API_KEY: ${{ secrets.LANGCHAIN_API_KEY }}
LANGCHAIN_TRACING_V2: "true"
OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }}
run: python scripts/run_eval.py
Add your secrets to GitHub: Settings → Secrets → Actions → add LANGCHAIN_API_KEY and OPENAI_API_KEY.
Verification
Open a PR that changes a prompt or model setting. The Actions tab should show the LLM Regression Tests job running.
# Simulate a regression locally before pushing
python scripts/run_eval.py
You should see:
Running eval against dataset: qa-regression-v1
Pass threshold: 0.85
Results: 3 examples evaluated
Average semantic_accuracy: 0.967
PASS: 0.967 meets threshold 0.85
To test the failure path, temporarily lower your threshold or introduce a bad prompt, then re-run.
In the LangSmith UI at smith.langchain.com, every CI run appears under Experiments grouped by ci-regression prefix. You can diff run-over-run score changes side by side.
 Caption: Each PR triggers a named experiment run — compare scores across commits to spot regressions
Caption: Each PR triggers a named experiment run — compare scores across commits to spot regressions
Advanced: Caching Dataset Pulls to Cut Latency
If your dataset has 100+ examples, fetching it on every PR adds latency. Cache the dataset as a JSON file in your repo and only refresh it when the dataset version changes.
# scripts/run_eval.py (extended version)
import json
import hashlib
from pathlib import Path
CACHE_PATH = Path(".langsmith_cache/dataset.json")
def load_or_fetch_dataset(client, dataset_name: str) -> list:
dataset = client.read_dataset(dataset_name=dataset_name)
cache_key = str(dataset.modified_at) # invalidate cache on dataset update
if CACHE_PATH.exists():
cached = json.loads(CACHE_PATH.read_text())
if cached.get("cache_key") == cache_key:
print("Using cached dataset")
return cached["examples"]
examples = list(client.list_examples(dataset_name=dataset_name))
CACHE_PATH.parent.mkdir(exist_ok=True)
CACHE_PATH.write_text(json.dumps({
"cache_key": cache_key,
"examples": [e.dict() for e in examples],
}))
return examples
Add .langsmith_cache/ to .gitignore and cache it in Actions:
- uses: actions/cache@v4
with:
path: .langsmith_cache
key: langsmith-dataset-${{ hashFiles('scripts/create_dataset.py') }}
Tuning Your Pass Threshold
Don't set PASS_THRESHOLD to 1.0 — LLM-as-judge scoring has variance, and flaky evals are worse than no evals.
| Scenario | Recommended threshold |
|---|---|
| LLM-as-judge (semantic) | 0.80 – 0.90 |
| Exact match (structured output) | 0.95 – 1.00 |
| RAG faithfulness | 0.75 – 0.85 |
| Code correctness (execution-based) | 0.90 – 1.00 |
Start at 0.80, run 5–10 PRs without intentional regressions, then raise the threshold to just below your observed average. This avoids false failures from model variance.
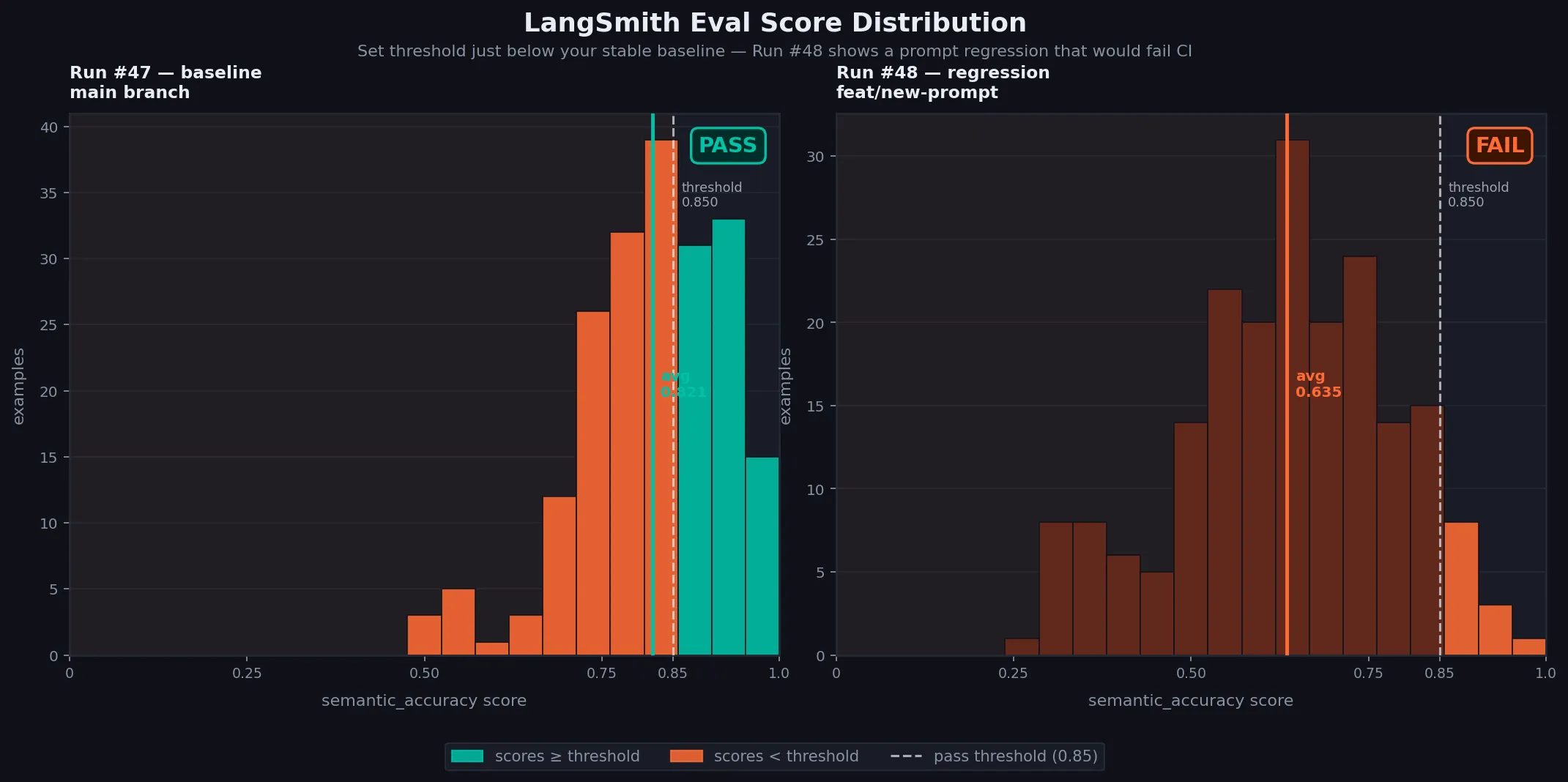 Caption: Visualize score variance before setting your threshold — a tight distribution means you can set a higher bar
Caption: Visualize score variance before setting your threshold — a tight distribution means you can set a higher bar
What You Learned
- LangSmith datasets are your regression fixtures — create them once, reuse on every PR
- The
evaluate()function handles parallelism, tracing, and result aggregation automatically sys.exit(1)in the eval script is all that's needed to fail a GitHub Actions job- LLM-as-judge evaluators handle fuzzy correctness; exact-match works for structured outputs
- Cache dataset fetches to keep CI fast when datasets grow beyond ~50 examples
Limitation: LLM-as-judge evaluators cost API tokens on every CI run. For 50 examples using gpt-4o-mini, expect ~$0.02 per run — cheap, but account for it at scale. For high-volume pipelines, write deterministic evaluators where possible.
 Caption: LangSmith's experiment diff view highlights which examples regressed between the base branch and your PR
Caption: LangSmith's experiment diff view highlights which examples regressed between the base branch and your PR
Tested on LangSmith SDK 0.2.x, LangChain 0.3.x, Python 3.12, GitHub Actions ubuntu-latest