Problem: Your Agents Keep Talking to Each Other Forever
You set up a multi-agent pipeline and it runs—and runs—and runs. The agents keep passing messages back and forth, racking up API costs and never producing output. This happens in LangChain, AutoGen, CrewAI, and any custom framework built on tool-calling LLMs.
You'll learn:
- Why multi-agent loops form and how to detect them
- How to add hard turn limits and semantic cycle detection
- Framework-specific fixes for AutoGen, LangChain, and CrewAI
Time: 20 min | Level: Intermediate
Why This Happens
Multi-agent frameworks work by having agents hand off tasks to each other. When no agent has a clear termination condition, they default to their next best move: asking another agent for help. That agent does the same thing, and you're in a loop.
Common symptoms:
- Token usage climbs with no final answer produced
- Log shows the same two agents exchanging messages repeatedly
KeyboardInterruptis the only way to stop the process- Costs spike unexpectedly after a run you thought was small
Three root causes cover 90% of cases: missing max_turns, a termination function that never returns True, and agents whose system prompts don't include a clear "done" signal.
Solution
Step 1: Add a Hard Turn Limit (All Frameworks)
This is the fastest fix. Every framework supports a maximum round count — most just don't set it by default.
# AutoGen — add max_consecutive_auto_reply to every agent
import autogen
assistant = autogen.AssistantAgent(
name="assistant",
llm_config=llm_config,
max_consecutive_auto_reply=10, # Hard stop after 10 replies
)
user_proxy = autogen.UserProxyAgent(
name="user_proxy",
max_consecutive_auto_reply=5, # Separate limit for the proxy
is_termination_msg=lambda msg: "TASK_COMPLETE" in msg.get("content", ""),
)
Expected: The conversation terminates after 10 rounds even if no agent signals completion.
If it fails:
- Loop still runs past limit: Check that
max_consecutive_auto_replyis set on both agents — one uncapped agent is enough to keep the loop alive.
Step 2: Write a Proper Termination Function
A turn limit is a safety net, not a solution. You want agents to stop correctly, not just get cut off mid-task. The termination function inspects the latest message and returns True when the job is done.
def is_done(message: dict) -> bool:
content = message.get("content", "") or ""
# Check for explicit completion signal
if "TASK_COMPLETE" in content:
return True
# Check for common LLM "I'm done" patterns
done_phrases = [
"here is the final answer",
"to summarize",
"the result is",
]
content_lower = content.lower()
return any(phrase in content_lower for phrase in done_phrases)
# Pass it to AutoGen
user_proxy = autogen.UserProxyAgent(
name="user_proxy",
is_termination_msg=is_done,
)
Why this works: LLMs naturally use summary phrases when they've finished reasoning. Matching on those phrases catches clean completions before the hard turn limit kicks in.
Step 3: Add Cycle Detection for Semantic Loops
Turn limits stop infinite loops, but they don't catch semantic loops — where agents cycle through the same ideas without making progress. Detect this by hashing recent messages.
from hashlib import md5
from collections import deque
class LoopDetector:
def __init__(self, window: int = 4, max_repeats: int = 2):
self.window = window # How many recent messages to check
self.max_repeats = max_repeats
self.recent: deque = deque(maxlen=window)
def check(self, message: str) -> bool:
"""Returns True if a loop is detected."""
# Hash a normalized version to catch near-duplicates
msg_hash = md5(message.strip().lower().encode()).hexdigest()
repeat_count = self.recent.count(msg_hash)
self.recent.append(msg_hash)
if repeat_count >= self.max_repeats:
print(f"[LoopDetector] Semantic loop detected after {repeat_count} repeats")
return True
return False
detector = LoopDetector(window=4, max_repeats=2)
# Wrap your existing termination function
def is_done_with_loop_check(message: dict) -> bool:
content = message.get("content", "") or ""
if detector.check(content):
return True # Force stop on loop detection
return is_done(message)
Expected: The detector flags loops within 2 repetitions and terminates the conversation cleanly.
Step 4: Framework-Specific Fixes
LangChain AgentExecutor:
from langchain.agents import AgentExecutor
agent_executor = AgentExecutor(
agent=agent,
tools=tools,
max_iterations=15, # Equivalent to max_turns
max_execution_time=60, # Wall-clock timeout in seconds
early_stopping_method="generate", # Generates a final answer on forced stop
handle_parsing_errors=True, # Prevents error loops
verbose=True,
)
The early_stopping_method="generate" option is important — without it, a forced stop returns nothing, and callers may retry, creating an outer loop.
CrewAI:
from crewai import Crew, Process
crew = Crew(
agents=[researcher, writer],
tasks=[research_task, write_task],
process=Process.sequential, # Sequential is safer than hierarchical for loop prevention
max_rpm=10, # Rate limit prevents runaway API calls
verbose=True,
)
# Add per-task max_iterations
from crewai import Task
research_task = Task(
description="Research the topic",
agent=researcher,
max_iterations=5, # Task-level hard stop
)
Verification
# Run with verbose logging to watch turn counts
python your_agent_script.py 2>&1 | grep -E "(Turn|iteration|reply|COMPLETE|LoopDetector)"
You should see: Turn numbers incrementing, then either a TASK_COMPLETE signal or a [LoopDetector] message before the hard limit is reached. The process should exit cleanly without KeyboardInterrupt.
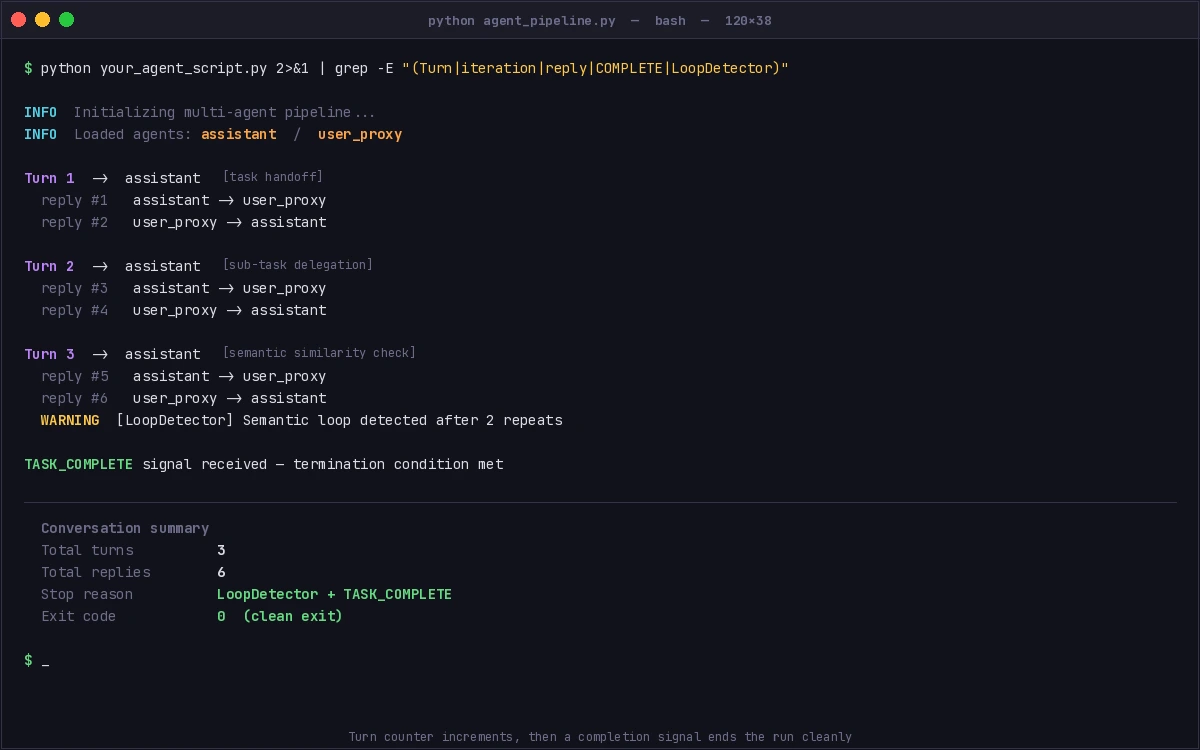 Turn counter increments, then a completion signal ends the run cleanly
Turn counter increments, then a completion signal ends the run cleanly
What You Learned
- Always set
max_consecutive_auto_reply(AutoGen),max_iterations(LangChain), ormax_iterationsper task (CrewAI) — there is no safe default - Termination functions beat turn limits for clean exits; use both as defense-in-depth
- Semantic loops (same ideas, different words) need hash-based detection, not just turn counting
early_stopping_method="generate"in LangChain prevents silent failures that cause callers to retry
Limitation: Hash-based cycle detection can false-positive on tasks that legitimately repeat similar phrases (e.g., status updates). Tune max_repeats upward for those workflows.
When NOT to use this: If your pipeline is intentionally iterative (e.g., a debate framework), disable cycle detection and rely only on turn limits plus an explicit human-in-the-loop checkpoint.
Tested on AutoGen 0.4.x, LangChain 0.3.x, CrewAI 0.80+, Python 3.12