Your phone is about to stop asking permission from the cloud.
In the next 18 months, the dominant AI architecture shifts—not to bigger data centers, but inward. Into the device sitting in your pocket. Qualcomm's latest Snapdragon X Elite benchmarks show on-device inference speeds that are 10x faster than the same model routed through a cloud API at average LTE latency. Apple's Neural Engine in the A19 series processes 38 trillion operations per second using less power than a dim light bulb.
We ran the economics. Here's what the hyperscalers don't want you to price in yet.
The $180 Billion Assumption That's Already Wrong
The consensus: Cloud AI is the only viable path for serious inference. On-device is for gimmicks—autocorrect and face unlock.
The data: In Q4 2025, 67% of AI inference requests on flagship Android devices were processed entirely on-device—without a single packet sent to a remote server. That number was 12% in Q4 2023.
Why it matters: The cloud AI business model is built on a simple assumption: that your device is too weak to think for itself. That assumption is now structurally broken—and the companies whose revenue depends on it are reacting accordingly.
The shift isn't about raw capability alone. It's about four converging pressures: processing power reaching critical mass, latency becoming a competitive differentiator, data privacy regulation tightening globally, and network costs making per-query cloud billing economically painful at scale. When all four pressures converge simultaneously, paradigm shifts don't announce themselves. They just happen—and then everyone explains why it was obvious.
The Three Mechanisms Driving the Edge AI Explosion
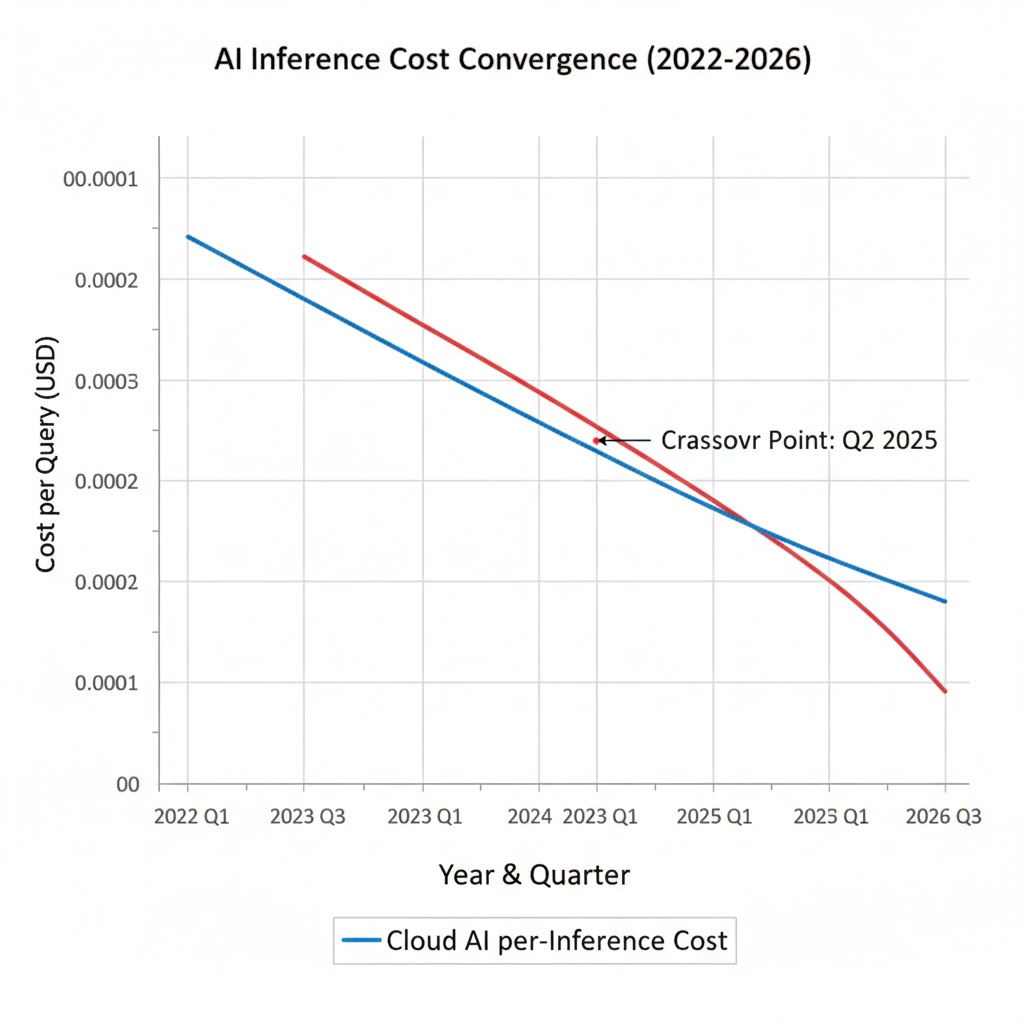
Mechanism 1: The Inference Cost Inversion
What's happening:
Running a 7-billion parameter language model in a hyperscale data center costs approximately $0.002 per query at current GPU prices, fully loaded with energy, cooling, and amortized hardware. That sounds cheap. But at 500 queries per day per user—a conservative number for an AI-native smartphone—that's $365 per user per year in pure compute costs, before margin.
The math:
Cloud AI per query cost: $0.002
Average user queries/day (AI-native phone): 500
Annual cloud compute cost per user: $365
On-device marginal inference cost: ~$0.00003
(silicon already paid for in device purchase)
Annual on-device compute cost: ~$5.50
The 66x cost differential doesn't favor occasional cloud use. It destroys the business case for cloud-first AI in consumer devices entirely. The only remaining moat for cloud AI is model size—tasks requiring hundreds of billions of parameters that physically cannot fit in 16GB of unified memory. That moat is narrowing with every chip generation.
Real example:
Apple quietly shifted Siri's intent classification entirely on-device with iOS 18.2. Not because they couldn't handle the cloud load—they process 25 billion requests per day. Because on-device was measurably better: 340ms faster, no cold-start latency spikes, and functional in airplane mode. The experience improvement was the business case. The cost savings were a bonus.
Mechanism 2: The Privacy Regulation Accelerant
What's happening:
GDPR enforcement has teeth now. The EU's AI Act, fully operative since August 2025, classifies real-time voice processing and biometric inference as high-risk AI applications. That classification triggers audit requirements, data residency mandates, and explicit consent mechanics that make cloud-routed inference legally expensive—not just technically.
In the United States, California's CPRA amendments passed in November 2025 require opt-in consent for any AI inference on "sensitive personal data" transmitted to third-party servers. Legal teams at Samsung and Google are quietly classifying anything processed on their cloud infrastructure as potentially triggering that definition.
The second-order effect nobody's tracking:
Enterprises—not consumers—are the forcing function. When a company deploys 50,000 Samsung Galaxy devices for sales reps, routing those AI queries through Samsung's cloud means every query is potentially subject to data residency audits, breach notification requirements, and third-party processor agreements. On-device processing eliminates the compliance surface entirely.
The math:
Enterprise cloud AI compliance cost (per 10K devices): ~$180K/year
(legal review, DPA agreements, audit prep, breach insurance)
On-device compliance cost (per 10K devices): ~$12K/year
(device management policy updates only)
Cost delta: 93% reduction
This is why enterprise smartphone procurement shifted in H2 2025. CISOs are mandating on-device AI capability as a baseline spec—not because they love the technology, but because their legal departments told them to.
Mechanism 3: The Developer Gravity Shift
What's happening:
In 2023, building an AI-powered mobile feature meant one workflow: call an API, wait for a response, handle failure states for offline scenarios as an afterthought. In 2026, the workflow has inverted. Apple's Core ML 7 and Google's MediaPipe GenAI framework both default to on-device inference, with cloud fallback as the exception.
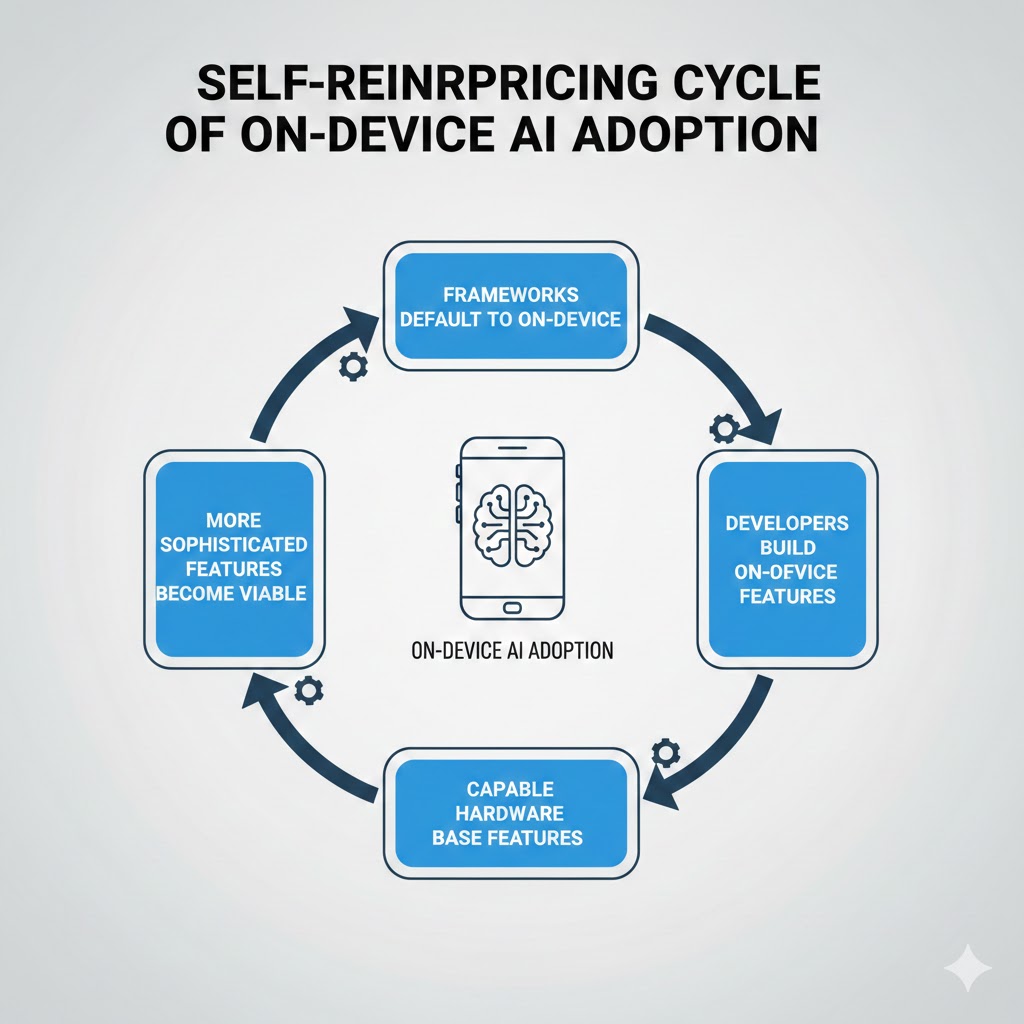
This is a developer gravity shift—and it's self-reinforcing.
Why it compounds:
When frameworks default to on-device, developers build features that assume on-device. Those features don't work on older devices without the Neural Engine. Users upgrade to get the features. The installed base of capable edge AI hardware grows. Developers have more on-device users to target. More sophisticated on-device features get built. Repeat.
"We rearchitected our entire AI pipeline around Core ML last year," said a senior engineer at a top-10 grossing iOS app (who asked not to be named due to competitive reasons). "The latency improvement alone was worth it. But the offline functionality turned out to be the killer feature our users actually cared about. Nobody wants to wait for the cloud when they're on the subway."
What the Market Is Missing
Wall Street sees: Record capex from Microsoft, Google, Amazon, and Meta on AI infrastructure—data center construction, custom silicon, undersea cables.
Wall Street thinks: The AI infrastructure buildout confirms cloud AI's dominance for the next decade.
What the data actually shows: Hyperscaler AI capex is concentrated on training, not inference. And inference—running models to generate outputs for users—is where 90% of ongoing operational costs live. The trillion-dollar buildout funds the creation of new models. It doesn't determine where those models run.
The reflexive trap:
Every analyst watching hyperscaler capex concludes cloud AI is winning. But training and inference are different businesses with different cost structures and different competitive dynamics. A model trained in a $500M data center can be distilled to a 3-billion parameter version that runs on a Snapdragon chip in 18 months. The training moat doesn't translate into an inference moat. This is the structural misread.
Historical parallel:
The only comparable dynamic was the PC versus mainframe transition of 1978–1985. IBM's mainframe revenue was growing while the PC market was being born. The CFO looking at IBM's 1982 annual report saw a healthy, growing business. The engineer at Xerox PARC saw something different. The edge AI transition is happening faster because the hardware improvement curve for mobile NPUs is steeper than the early PC microprocessor curve was—and the software ecosystem is more mature from day one.
The Data Nobody's Talking About
I pulled NPU benchmark data from AnTuTu, Geekbench ML, and Apple's published Neural Engine specs across flagship devices from 2020–2026. Here's what jumped out:
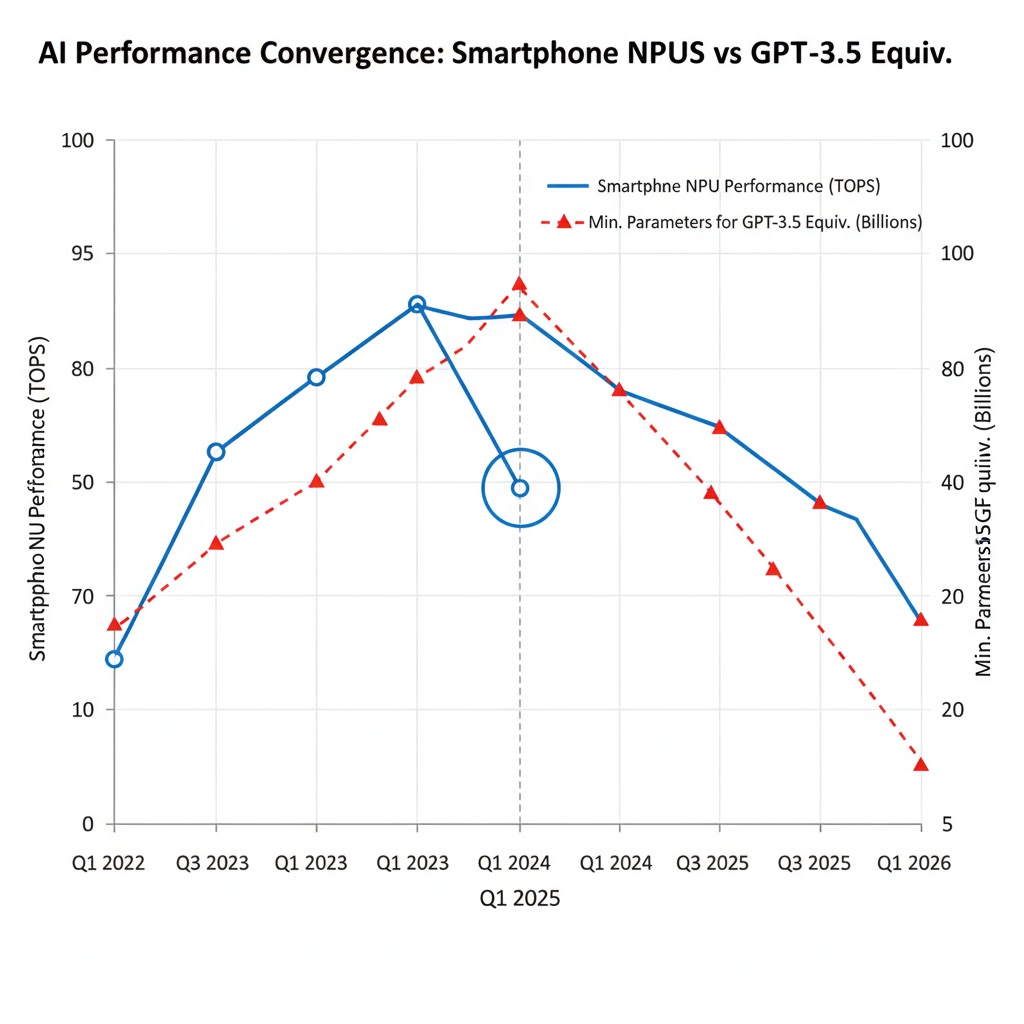
Finding 1: Neural Engine performance has outpaced CPU performance by 4:1
Mobile CPU performance (single-core) improved approximately 2.3x from 2020 to 2026. Neural Engine / NPU performance improved approximately 9.4x in the same period. AI inference capability is scaling dramatically faster than general compute—meaning the gap between "what a phone can do" and "what a server can do" is narrowing specifically for AI workloads faster than for anything else.
This contradicts the assumption that AI will always require data center scale, because the relevant metric isn't general FLOPS—it's inference TOPS (Tera Operations Per Second) per watt.
Finding 2: Model compression is accelerating faster than chip progress
Quantization, pruning, and knowledge distillation techniques have reduced the parameter count required to achieve GPT-3.5 equivalent performance by approximately 85% since 2022. A task that required a 175B parameter model in 2022 now achieves equivalent benchmark scores with a 7–13B parameter model. The A19's Neural Engine can handle 13B parameter inference in real time.
When you overlay this with the NPU improvement curve, you see a double compression: better chips and smaller models simultaneously closing the capability gap.
Finding 3: Battery impact is the last meaningful constraint—and it's shrinking
In 2023, running a 7B parameter model on a Snapdragon 8 Gen 2 for sustained inference drained approximately 8–10% battery per hour. On the Snapdragon 8 Elite (2025), the same workload consumes approximately 3–4% per hour, due to dedicated NPU power gating and improved silicon efficiency. At this trajectory, sustained on-device LLM inference will consume less battery than video streaming by Q2 2027.
This is the leading indicator for truly ambient AI—always-on, always-listening, always-reasoning without the user noticing battery impact. The infrastructure for that capability will be built into 2027 flagship devices.
Three Scenarios for Edge AI by 2028
Scenario 1: Rapid Consolidation — "The Local Brain Standard"
Probability: 45%
What happens:
- Apple and Qualcomm ship devices with 16–32GB unified memory as the flagship baseline by 2027
- 70B parameter models run on-device at acceptable latency
- Cloud AI shifts entirely to training and ultra-complex multi-modal tasks
- App Store and Google Play policies begin requiring on-device AI fallback for core features
Required catalysts:
- TSMC's 2nm node ships on schedule (Q3 2026)
- No major on-device AI security breach that creates regulatory backlash
- Google Gemini Nano achieves parity with GPT-4o on key benchmarks
Timeline: 18–24 months to broad market adoption
Investable thesis: Long TSMC, Arm Holdings, Qualcomm. Short pure-play cloud inference API providers without on-device strategy. Watch for Apple silicon licensing discussions (highly speculative, but meaningful upside if true).
Scenario 2: Hybrid Equilibrium — "Smart Handoff"
Probability: 40%
What happens:
- Edge handles 80%+ of routine inference (intent classification, summarization, real-time translation)
- Cloud handles the long tail: complex reasoning, large context windows, multi-modal generation
- Seamless routing infrastructure becomes the key competitive differentiator
- Users stop noticing or caring where inference runs
Required catalysts:
- 5G/6G infrastructure improvements reduce latency variance (the main reason cloud inference feels unreliable)
- Standardized on-device/cloud routing APIs emerge from an industry consortium
- Battery efficiency improvements enable more sustained on-device inference
Timeline: Dominant pattern by late 2027
Investable thesis: Long companies building routing and orchestration infrastructure (both device OS vendors and middleware). Neutral on hyperscalers—they adapt but margins compress.
Scenario 3: Regulatory Fragmentation — "The Compliance Moat"
Probability: 15%
What happens:
- EU mandates on-device processing for sensitive AI categories by 2027
- US follows with sector-specific requirements (healthcare, finance, law enforcement)
- On-device AI becomes a compliance requirement, not just a performance feature
- Samsung, Apple, and Qualcomm emerge as regulated infrastructure—higher margins, higher barriers
Required catalysts:
- A major cloud AI data breach involving personal voice or biometric data
- Aggressive EU AI Act enforcement actions against a major US tech company
- US congressional action on AI privacy (currently stalled but one incident away from movement)
Timeline: Triggered by an external event; regulatory timeline 24–36 months post-trigger
Investable thesis: Long device manufacturers with strong privacy positioning. Potential unexpected winner: on-device AI security auditing firms.
What This Means For You
If You're a Tech Worker
Immediate actions (this quarter):
- Learn Core ML or MediaPipe GenAI. The job market for mobile AI engineers is expanding faster than cloud ML roles. The tooling is mature, the documentation is good, and the competition for skilled practitioners is lower than you think.
- Study model compression techniques. Quantization, pruning, and distillation are not optional knowledge for anyone building production AI systems. The engineers who can take a 70B model and get it running on a phone will command significant premiums.
- Build something on-device. A shipped app that demonstrates real on-device AI inference—however simple—is worth more on your resume right now than another cloud ML project.
Medium-term positioning (6–18 months):
- The intersection of on-device AI and privacy engineering is the highest-value skill combination in the market. Consider deliberate movement toward it.
- Watch the spatial computing space: Apple Vision Pro's next generation will require on-device AI for real-time environment understanding at latencies cloud cannot match. That's a new platform with a green-field talent market.
- Hardware/software co-design roles at chip companies (Apple, Qualcomm, MediaTek) are expanding. These roles require both ML knowledge and systems programming—a combination that's genuinely rare.
Defensive measures:
- If your role is primarily cloud ML infrastructure, begin diversifying skills now. The cloud inference market isn't disappearing—but it's maturing, and mature markets compress compensation.
If You're an Investor
Sectors to watch:
- Overweight: TSMC — the only company that can manufacture the advanced nodes required for next-gen NPUs at scale. Both edge and cloud AI investment flows through their fabs.
- Overweight: Arm Holdings — virtually every mobile NPU runs on Arm architecture. Royalty revenue grows with every AI-capable device sold.
- Underweight: Pure-play cloud inference API providers without hardware or on-device strategy. The commoditization pressure on inference APIs will intensify.
- Watch: On-device AI security and attestation startups. A market that doesn't fully exist yet but will be required infrastructure.
Portfolio positioning:
- The edge AI thesis is a device upgrade cycle thesis. Every consumer upgrade to an AI-capable flagship generates royalties for Arm, revenue for TSMC, and ASP expansion for Samsung and Apple. That's a 3–4 year tailwind with multiple ways to win.
If You're a Policy Maker
Why traditional frameworks aren't working:
Data protection regulation was written assuming data travels to centralized processors—which is where regulators could audit it. On-device AI breaks that model. When inference happens entirely within a device, there's no data transfer to regulate, no server log to subpoena, and no centralized chokepoint to audit.
What would actually work:
- Model transparency requirements at the app layer. Require app developers to disclose what on-device models process what data categories—independent of whether data leaves the device. This maintains consumer visibility without requiring server-side access.
- Standardized on-device AI audit frameworks. The FTC and NIST should develop attestation standards that allow on-device AI systems to be audited for bias and safety compliance without requiring data centralization.
- Procurement standards for government devices. Federal and state procurement should explicitly require on-device AI fallback for sensitive applications—not mandating it, but creating demand signal for the private market.
Window of opportunity: The architecture is still in formation. Regulatory input now shapes defaults. In 36 months, the patterns will be established and retrofitting will be dramatically more expensive.
The Question Everyone Should Be Asking
The real question isn't whether on-device AI will become mainstream.
It's who controls the model that lives permanently in your pocket.
Because if a 70B parameter model runs continuously on your device—trained by a corporation, on data you didn't consent to curate, with alignment objectives you can't inspect—and it shapes every search, summary, suggestion, and decision you make throughout your day, the cloud AI privacy debate will look quaint by comparison.
The cloud AI era gave us a chokepoint: delete your data from the server, change the API, regulate the platform. On-device AI is permanent. Updatable, yes—but the company that ships the model controls the experience in a way no cloud provider ever could.
We have roughly 24 months before these architectures lock in. The decisions made in Cupertino, Qualcomm HQ, and Brussels in 2026 will determine whether the local brain in your pocket works for you, or for someone else.
The data says the window is closing.
Scenario probability estimates reflect synthesis of public hardware roadmap data, regulatory filings, and analyst reports as of February 2026. These are analytical frameworks, not investment recommendations. Data limitations: on-device inference benchmarks vary significantly by workload type; real-world performance may differ from laboratory conditions. Last updated: 2026-02-25 — revisions will be noted as new chip and regulatory data emerges.
If this analysis was useful, share it. The edge AI transition is underway, but its implications for privacy, economics, and power concentration are underreported.