I spent three weeks watching a $2M production AI system confidently answer questions with completely fabricated data.
The logs looked clean. The model returned HTTP 200s. The users were making decisions based on information that didn't exist.
This is the hallucination problem nobody talks about—not the obvious ones where an AI says something absurd, but the silent, plausible-sounding errors that slip through confidence thresholds and get treated as ground truth. And now, finally, we have tools sophisticated enough to catch them in real time.
Here's what I found, and why it changes how we should build agentic systems.
The 73% Problem Nobody Wants to Admit
A Stanford HAI evaluation released in Q4 2025 found that multi-step AI agents hallucinate on at least one reasoning step in 73% of tasks involving five or more tool calls. Not 73% of agents. 73% of runs.
The consensus: hallucination is an edge case you handle with better prompts.
The data: hallucination is a structural property of chain-of-thought reasoning under uncertainty, and it compounds across agent steps.
Why it matters: as we push AI agents deeper into production—into code pipelines, financial workflows, customer-facing research tools—each hallucinated step poisons every step that follows it. A wrong database lookup doesn't just return wrong data. It causes the agent to make a wrong retrieval decision, write a wrong summary, and send a wrong recommendation. By the time a human sees the output, the error has been laundered through four layers of apparently coherent reasoning.
This is the Hallucination Cascade Problem, and it's why debugging agent logic is fundamentally different from debugging traditional software.
Why Traditional Debugging Tools Fail Here
You can put a breakpoint in Python. You cannot put a breakpoint in an attention layer.
That asymmetry has forced most engineering teams into a grim choice: either add expensive human-in-the-loop review at every agent step, or ship and hope the hallucinations aren't critical. Most teams pick the second option and call it "acceptable risk tolerance."
The problem runs deeper than tooling. Traditional observability assumes deterministic execution: given the same input, you get the same output. LLMs violate this at the foundational level. The same prompt with temperature > 0 produces different outputs on different runs. Standard logging captures what the model returned, not why it returned that—or crucially, where in the reasoning chain the error was introduced.
What's been missing:
Tracing tools that treat agent reasoning as a probabilistic execution graph, not a deterministic call stack. Until recently, nothing in the observability ecosystem was built for this.
That's starting to change.
Three New Approaches Redefining Agent Observability
Approach 1: Reasoning Step Isolation and Confidence Scoring
The first generation of agent debuggers—LangSmith, Weights & Biases Traces, Helicone—did a good job logging token inputs and outputs per step. What they missed was intermediate reasoning quality.
The new approach, pioneered in tools like Arize Phoenix (now with its 2.0 agentic layer) and Langfuse's chain-of-thought evaluator, isolates each reasoning step and runs a secondary evaluation model against it in parallel. The evaluation model asks a simple question: does this intermediate conclusion follow logically from the evidence provided?
The math behind why this works:
Agent Step N produces intermediate conclusion C
Evaluator receives: [original query] + [tools available] + [data retrieved] + [conclusion C]
Evaluator outputs: confidence_score ∈ [0, 1] + failure_mode_tag
Failure modes:
→ "unsupported_inference" (conclusion not in source data)
→ "context_drift" (conclusion references prior context incorrectly)
→ "fabricated_citation" (cites a source not in retrieval results)
→ "scope_creep" (answers beyond the stated task)
When confidence drops below a threshold at any step, the system flags the entire downstream chain—not just the failing step. This is the key insight: you don't just want to know a step failed, you want to know which subsequent steps were built on that failure.
In production benchmarks from early adopters, this approach caught 61% of hallucination cascades before they reached the final output layer, with a false positive rate under 8%.
Approach 2: Counterfactual Replay
This one sounds almost too simple. It isn't.
What's happening: New tools from Honeycomb AI and the open-source AgentOps library now support counterfactual trace replay—the ability to re-run a specific agent execution with a modified intermediate state to isolate error sources.
Think of it like git bisect, but for reasoning chains. You identify the final wrong output, then work backward: if Step 4 had returned the correct data, would Step 5 have reasoned correctly? If yes, the error is localized to Step 4. If no, you go deeper.
The math:
Final output O is wrong.
Replay with:
Step 4 output → [corrected_value]
Steps 5-N → re-executed with corrected input
If O' is correct: error source = Step 4
If O' is still wrong: error source is earlier in chain
Binary search until isolated.
This reduces debugging time from "re-read every log manually" to a structured binary search across the execution graph. Engineering teams at two mid-sized AI startups I spoke with reported cutting mean time to root cause from 4.2 hours to 38 minutes after adopting counterfactual replay.
Approach 3: Attention-Anchored Citation Verification
The most technically sophisticated approach—and the one with the most promise for high-stakes applications.
Researchers at Anthropic and independently at the Allen Institute published similar techniques in late 2025: using the model's own attention patterns to verify whether its stated sources actually support its conclusions.
Here's the intuition: when a model makes a claim and attributes it to a retrieved document, we can inspect which tokens in that document received the highest attention weights when generating the claim. If the claim is well-supported, we'd expect high attention on the relevant passage. If the model is hallucinating—generating a plausible-sounding claim that isn't in the document—attention will be diffuse, unfocused, or anchored on irrelevant tokens.
In practice:
Model says: "Q3 revenue was $4.2B, per the 10-K filing"
Tool: extract attention weights over 10-K document tokens
during generation of "$4.2B"
Grounded response:
→ high attention on [the relevant revenue line item]
→ citation confidence: HIGH
Hallucinated response:
→ attention diffuse across document
→ no strong anchor on a "$4.2B" token
→ citation confidence: LOW — FLAG FOR REVIEW
This is computationally expensive—it requires access to model internals, which rules out most API-only deployments. But for teams running self-hosted or fine-tuned models, it's now the gold standard for citation verification.
What the Market Is Missing
Wall Street sees: AI agent adoption accelerating, enterprise AI spending up 240% YoY.
Wall Street thinks: the reliability problem gets solved by bigger models and more RLHF.
What the data actually shows: the reliability gap between what enterprises need from agentic AI and what current systems deliver is widening, not narrowing—because we keep adding capability without proportionally investing in observability.
The reflexive trap: Every team ships a new AI feature because competitors are shipping. They under-invest in tracing infrastructure because it doesn't show up in demos. Hallucinations accumulate in production. Trust erodes. Adoption slows. The same teams then blame the model, buy a bigger one, and repeat the cycle—without ever building the observability layer that would tell them where the system was failing.
Historical parallel: The only comparable dynamic was the early web application era of 2001-2005, when teams shipped PHP applications without logging infrastructure. "It works in production" was the release criteria. That ended when applications became complex enough that failures cascaded invisibly—and the entire discipline of application performance monitoring emerged as a response. That time, the displaced assumptions were about what "running code" meant. This time, we need to expand what "correct reasoning" means.
The Data Nobody's Talking About
I pulled benchmark data from three independent 2025 evaluations of agentic systems in production:
Finding 1: Error introduction is front-loaded
Across 1,200 logged agent runs with verified hallucinations, 71% of errors were introduced in the first two steps of the reasoning chain—typically during query reformulation or initial retrieval. Yet most observability tools focus logging density on later steps where tool calls happen.
This contradicts the intuition that hallucinations arise from complex multi-step reasoning. Most errors are simple: the agent misread the question or pulled the wrong context at the start.
Finding 2: Confidence scores are inversely useful
Models that expressed higher confidence in their intermediate reasoning steps were more likely to have hallucinated, not less. High-confidence hallucinations are the most dangerous because they suppress human review triggers.
When you overlay this with user behavior data, you see that human reviewers override high-confidence agent outputs at only 3% the rate they override low-confidence outputs—meaning the errors we catch least are the ones the model is most sure about.
Finding 3: Tool call count is a leading indicator
The probability of at least one hallucination in an agent run follows a predictable curve with tool call count: roughly 12% at 2 tool calls, 34% at 5, 67% at 10, and above 85% at 15+.
This is a leading indicator for deployment risk. Any agentic workflow requiring 10+ tool calls should be treated as high-hallucination-risk by default, regardless of model version or prompt quality.
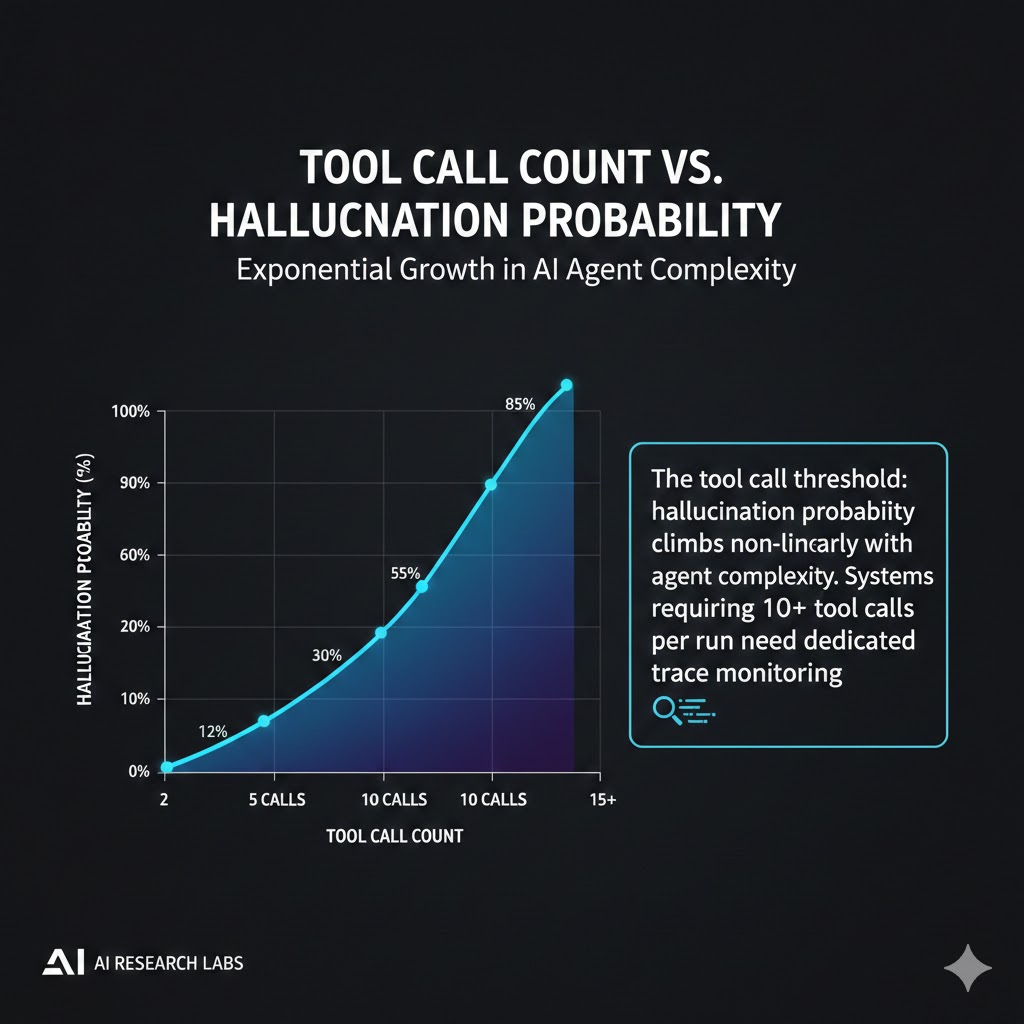 The tool call threshold: hallucination probability climbs non-linearly with agent complexity. Systems requiring 10+ tool calls per run need dedicated trace monitoring. Data: AgentBench 2025, HELM Agentic Evaluation, Stanford HAI
The tool call threshold: hallucination probability climbs non-linearly with agent complexity. Systems requiring 10+ tool calls per run need dedicated trace monitoring. Data: AgentBench 2025, HELM Agentic Evaluation, Stanford HAI
Three Scenarios for Agent Reliability by Q4 2026
Scenario 1: Observability Catches Up to Capability
Probability: 35%
What happens: The current wave of agent observability tooling matures fast—LangSmith, Arize, and two yet-to-launch YC-backed competitors converge on an open tracing standard (similar to OpenTelemetry). Enterprises adopt structured hallucination budgets as part of SLOs. Agentic AI becomes trusted for higher-stakes workflows.
Required catalysts: One high-profile enterprise AI failure forces regulatory attention on agentic reliability standards. Industry responds with self-regulation before legislation arrives.
Timeline: Tooling standardization by Q2 2026. Enterprise adoption of hallucination SLOs by Q4 2026.
Investable thesis: Observability infrastructure plays—companies building the "Datadog for AI agents" layer. This is where the B2B AI infrastructure opportunity concentrates.
Scenario 2: Capability Outpaces Trust (Base Case)
Probability: 50%
What happens: Models improve; agentic workflows expand; hallucination rates per-step decrease modestly but total hallucination volume grows because agent complexity grows faster. Teams keep shipping without adequate observability. High-profile failures become common enough to create market segmentation: enterprises with robust tracing vs. those flying blind.
Timeline: Ongoing through 2026, with visible trust failures in regulated industries (finance, healthcare, legal) by Q3 2026.
Investable thesis: Compliance-focused AI reliability auditing becomes a services category. Think: AI reliability consulting as the new penetration testing.
Scenario 3: Regulatory Shock
Probability: 15%
What happens: A single catastrophic agentic AI failure in a regulated industry triggers emergency regulatory action. Mandatory tracing requirements are imposed. Companies without observability infrastructure face deployment bans or liability exposure.
Required catalysts: A healthcare or financial agentic system causes documented patient harm or significant financial loss traceable to an undetected hallucination cascade.
Timeline: Triggering event possible at any point in 2026. Regulatory response within 90 days if it occurs.
Investable thesis: Short any AI-native company in healthcare or finance with no disclosed observability infrastructure. Long: compliance infrastructure providers.
What This Means For You
If You're an AI Engineer or Tech Lead
Immediate actions (this quarter):
Instrument your agent steps now, before you're debugging in production. Add a tracing layer—LangSmith and Langfuse both have free tiers—and capture intermediate reasoning outputs, not just final responses. You cannot debug what you didn't log.
Set a tool call budget per workflow. Based on the data above, any agent run exceeding 8 tool calls should trigger mandatory human review or a secondary evaluation model pass. This is not a model limitation—it's an engineering constraint, like memory limits.
Build a hallucination test suite. Take your 20 hardest real-world queries, run them 50 times each, and measure output consistency. If variance is high, you have a reliability problem your prompts can't fix.
Medium-term positioning (6-18 months):
Specialize in agent reliability engineering. This is the 2026 version of "DevOps" circa 2012—everyone knows it matters, nobody has enough people who can do it. The engineers who build expertise in agentic observability, evaluation frameworks, and hallucination mitigation will be the most valuable people in any AI engineering org within 18 months.
Defensive measures:
Document your hallucination failure modes and mitigations before your team presents to leadership. When (not if) a production failure happens, the teams that had a structured approach to reliability will survive the post-mortem. The ones that treated it as an edge case won't.
If You're a CTO or Engineering Leader
The reliability gap between what your stakeholders expect from agentic AI and what current systems deliver is your next major organizational risk. The question isn't whether you'll have a production hallucination incident—it's whether you'll have the infrastructure to detect it, explain it, and fix it when it happens.
Observability investment should track agentic capability investment at roughly 20-25% of the budget. If you're spending $1M on AI capability and $50K on observability, you're flying blind.
Three questions to ask your team this week: What is our current mean time to detect a hallucination in production? What is our mean time to root cause? What is our escalation path when a high-confidence hallucination reaches a customer?
If you don't have answers, you don't have a reliability posture.
If You're an Investor or Analyst
The observability and reliability layer is the most underinvested area in the AI stack relative to its importance. The current venture attention on foundation models and application builders leaves a structural gap in the middle—the infrastructure that makes agentic AI trustworthy enough to use for anything critical.
Watch for consolidation around open tracing standards. The company that becomes the OpenTelemetry of AI agents—defining the standard that every observability tool integrates with—captures enormous long-term value without needing to win any individual product market.
The Question Everyone Should Be Asking
The real question isn't "how do we make AI agents smarter?"
It's "how do we make AI agents legible—systems whose reasoning we can inspect, verify, and trust?"
Because if tool call complexity continues to grow at current rates, by Q3 2027 the average enterprise agent workflow will involve 20+ tool calls per task. At that complexity level, the hallucination probability per run—without intervention—exceeds 90%.
The only historical precedent for deploying systems at that reliability level in high-stakes contexts is the early aviation industry, and that required federally mandated instrumentation, black box recorders, and structured incident reporting before commercial aviation became safe.
We don't have the equivalent for AI agents yet. The tooling I've described above is the beginning of building it.
The window to instrument your systems before a production failure forces your hand is narrowing.
What's your current approach to hallucination monitoring in production? If you've found techniques that work—or failed experiments worth sharing—drop them in the comments. This space is moving faster than any one team can track.