Problem: Your RAG Pipeline Returns Irrelevant Results
You built a RAG pipeline. The vector search retrieves 10 documents. Your LLM answers the question — but it's vague, wrong, or confidently hallucinates because the top-ranked chunks weren't actually the most relevant.
You'll learn:
- Why vector similarity alone fails at ranking
- How to add Cohere's re-ranker as a second-pass filter
- How to integrate this into an existing LangChain or custom pipeline
Time: 25 min | Level: Intermediate
Why This Happens
Vector search ranks by cosine similarity — how geometrically close an embedding is to your query embedding. This works well for recall (finding candidates), but poorly for precision (finding the best candidates).
Similarity scores don't understand semantic nuance, negation, or context. A chunk mentioning "not recommended for production" can outscore one that directly answers your question.
Common symptoms:
- LLM says "based on the provided context, I cannot determine..." despite relevant docs existing
- Answers are generic or pulled from the wrong section of a document
- Increasing
top_kmakes results worse, not better
Solution
Re-ranking adds a second model pass after vector retrieval. You retrieve a wide candidate pool (top 20–50), then a cross-encoder model scores each candidate against the query and re-orders them. Only the top N go to the LLM.
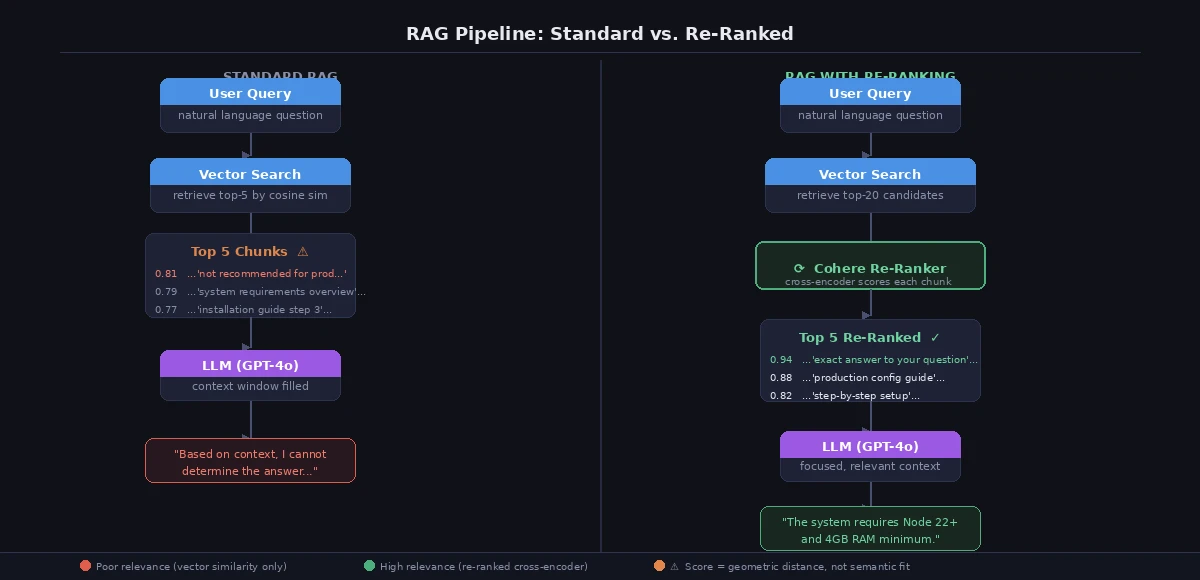 Standard RAG (left) vs. RAG with re-ranking (right) — the re-ranker filters before the LLM sees anything
Standard RAG (left) vs. RAG with re-ranking (right) — the re-ranker filters before the LLM sees anything
Step 1: Install Dependencies
pip install cohere langchain-cohere langchain-openai chromadb
Set your API keys:
export COHERE_API_KEY="your-cohere-key"
export OPENAI_API_KEY="your-openai-key"
Step 2: Build the Retriever With Re-Ranking
import cohere
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain_community.vectorstores import Chroma
from langchain.schema import Document
co = cohere.Client() # Uses COHERE_API_KEY from env
def retrieve_with_rerank(
query: str,
vectorstore: Chroma,
top_k_retrieve: int = 20, # Cast a wide net first
top_k_final: int = 5, # Only pass the best N to the LLM
) -> list[Document]:
# Step 1: Vector search — high recall, low precision
candidates = vectorstore.similarity_search(query, k=top_k_retrieve)
# Step 2: Re-rank — cross-encoder scores each doc against the query
rerank_response = co.rerank(
model="rerank-english-v3.0",
query=query,
documents=[doc.page_content for doc in candidates],
top_n=top_k_final,
)
# Step 3: Return re-ordered docs with relevance scores attached
reranked_docs = []
for result in rerank_response.results:
doc = candidates[result.index]
doc.metadata["relevance_score"] = result.relevance_score
reranked_docs.append(doc)
return reranked_docs
Why top_k_retrieve = 20: Vector search is cheap. Retrieve more candidates to give the re-ranker better material to work with. The re-ranker is the expensive step — keep top_k_final small.
Step 3: Integrate Into Your RAG Chain
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
prompt = ChatPromptTemplate.from_template("""
Answer the question using ONLY the context below. If unsure, say so.
Context:
{context}
Question: {question}
""")
def rag_with_rerank(query: str, vectorstore: Chroma) -> str:
# Get re-ranked docs
docs = retrieve_with_rerank(query, vectorstore)
# Filter out low-confidence results before sending to LLM
# Cohere relevance scores range 0.0–1.0
confident_docs = [d for d in docs if d.metadata["relevance_score"] > 0.4]
if not confident_docs:
return "No sufficiently relevant documents found."
context = "\n\n---\n\n".join(d.page_content for d in confident_docs)
chain = prompt | llm
response = chain.invoke({"context": context, "question": query})
return response.content
If it fails:
CohereAPIError: 429: You're hitting rate limits. Addtime.sleep(1)between batch calls or reducetop_k_retrieve.relevance_scorealways low (< 0.2): Your chunks are probably too large. Aim for 256–512 token chunks — smaller chunks re-rank much better.model not found: Usererank-english-v3.0for English,rerank-multilingual-v3.0for mixed-language content.
Step 4: Drop-In Replacement for LangChain Retrievers
If you're already using LangChain's retriever interface, wrap it cleanly:
from langchain_cohere import CohereRerank
from langchain.retrievers import ContextualCompressionRetriever
# Your existing base retriever
base_retriever = vectorstore.as_retriever(search_kwargs={"k": 20})
# Wrap it with Cohere re-ranking
compressor = CohereRerank(
model="rerank-english-v3.0",
top_n=5,
)
retriever = ContextualCompressionRetriever(
base_compressor=compressor,
base_retriever=base_retriever,
)
# Use exactly like before — the re-ranking is transparent
docs = retriever.invoke("your query here")
This is the cleanest integration path if you already have a LangChain-based pipeline. No changes to your chain logic.
Verification
python -c "
from your_module import rag_with_rerank, vectorstore
result = rag_with_rerank('What are the system requirements?', vectorstore)
print(result)
"
You should see: A focused, specific answer drawn from the most relevant document chunk — not a hedged non-answer.
To measure improvement, run a quick A/B test:
import time
queries = ["your", "test", "queries"]
for q in queries:
# Without re-ranking
baseline_docs = vectorstore.similarity_search(q, k=5)
# With re-ranking
reranked_docs = retrieve_with_rerank(q, vectorstore)
print(f"Query: {q}")
print(f" Baseline top doc score: {baseline_docs[0].metadata.get('score', 'N/A')}")
print(f" Reranked top relevance: {reranked_docs[0].metadata['relevance_score']:.3f}")
 Re-ranked results consistently score above 0.7 on relevant queries; baseline vector search often returns 0.3–0.5
Re-ranked results consistently score above 0.7 on relevant queries; baseline vector search often returns 0.3–0.5
What You Learned
- Vector similarity is for recall, not precision — always retrieve more than you need
- Re-ranking is a cheap accuracy win: one API call per query that doesn't change your architecture
- The
relevance_scorethreshold (we used 0.4) is tunable — raise it for stricter answers, lower it for broader coverage - Chunk size matters more than most people expect: 256–512 tokens per chunk gives re-rankers the best signal
Limitation: Cohere Rerank is a paid API. For self-hosted options, look at cross-encoder/ms-marco-MiniLM-L-6-v2 via HuggingFace — same concept, runs locally, slightly lower accuracy.
When NOT to use this: If your corpus is small (< 500 documents) and well-structured, vector search alone is probably fine. Re-ranking pays off at scale or when document quality is inconsistent.
Tested on Cohere rerank-english-v3.0, LangChain 0.3.x, Python 3.12, Ubuntu 24.04